Int8 quantization and tvm implementation
There are two main options for quantification
- Direct training quantitative models such as Deepcompression, Binary-Net, Tenary-Net, Dorefa-Net
- Directly quantify the trained float model (using float32 as an example) (using int8 as an example). This blog mainly talks about this.
Int8 quantization principle
Change the existing float32 type data to A = scale_A * QA + bias_A, B is similar, NVIDIA experiment proves that bias can be removed, ie A = scale_A * QA
is also QA (quantized A) = A / scale_A

With the corresponding formula A = scale_A * QA, the data of float32 can be mapped to int8, but since the data dynamic range of float32 is much larger than int8, if the data distribution is uneven, the limit For example, if the original data of float32 is around 127, the final quantization is 127, the precision loss is serious, and the other values of int8 are not used at all. The value range of int8 is not fully utilized, so the direct maximum and minimum mapping is not one. best plan.
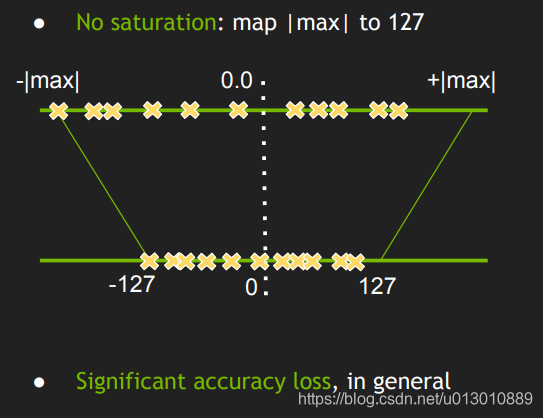
Can you find a threshold, discard a portion of the float32 value, and then map it more evenly, making full use of the value range of int8
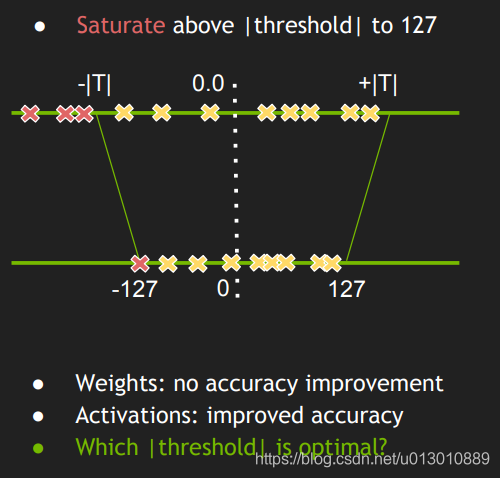
inThe principle of Softmax explainsMentioned in
cross entropy = entropy + KL divergence (relative entropy)
1) Information Entropy: What is the minimum average encoding length when the encoding scheme is perfect.
2) Cross entropy: What is the average encoding length when using suboptimal encoding, that is, how many bits are needed to represent
average encoding length = minimum average encoding length + one increment
3) Relative Entropy: The increase in the average code length relative to the minimum value when the coding scheme is not necessarily perfect. (ie the increment above)
Int8 encoding length required for encoding = encoding length required for float32 encoding + int8 required encoding length
So the relative entropy is that the int8float32 (suboptimal encoding) is smaller than the float32 (optimal encoding). The smaller the encoding length, the better, so you need to find a suitable threshold, so that between Minimum relative entropy, ie KL divergence
This KL distance represents the loss information

How to find a suitable threshold, you need a calibration set Calibration Dataset to run FP32 reasoning on the calibration data set. Collect the activated histogram and generate a set of 8-bit representations with different thresholds and select the representation with the least kl divergence; kl-divergence is between the reference distribution (ie FP32 activation) and the quantized distribution (ie 8 Bit quantization is activated between).

TVM implements int8 quantization
# From front-end load model, mxnet, onnx, etc.
sym, _ = relay.frontend.from_mxnet(sym, {'data': data_shape})
# Randomly generate test model parameters, if there are trained model parameters can be ignored
sym, params = tvm.relay.testing.create_workload(sym)
#
with relay.quantize.qconfig(skip_k_conv=0, round_for_shift=True):
sym = relay.quantize.quantize(sym, params)
#Model optimization (after experimentation, the tvm system has some common reset convolution optimizations by default. Note that this optimization is bound to the convolution configuration including the number of input and output kernels)
# If you use the system's existing convolution optimization configuration, the speed is guaranteed. If you use some novel convolution structure, you need to use auto tuning optimization, otherwise it is very slow.
Reference https://docs.tvm.ai/tutorials/autotvm/tune_relay_cuda.html#auto-tuning-a-convolutional-network-for-nvidia-gpu
# load optimal optimization operator, then compile the model
with autotvm.apply_history_best(log_file):
print("Compile...")
with relay.build_config(opt_level=3):
graph, lib, params = relay.build_module.build(
net, target=target, params=params)
#Load parameters and run
ctx = tvm.context(str(target), 0)
module = runtime.create(graph, lib, ctx)
data_tvm = tvm.nd.array((np.random.uniform(size=input_shape)).astype(dtype))
module.set_input('data', data_tvm)
module.set_input(**params)
# module.set_input(**{k:tvm.nd.array(v, ctx) for k, v in params.items()})
module.run()
#test forward time
e = module.module.time_evaluator("run", ctx, number=2000, repeat=3)
t = module(data_tvm).results
t = np.array(t) * 1000
print('{} (batch={}): {} ms'.format(name, batch, t.mean()))
Some code links for tvmtvm-cuda-int8-benchmark
- Int8 Quantization - Introduction (1)
- Int 8 quantization
- How to explain the cross entropy and relative entropy in a popular way? Zhang Yishan answered
- tvm tutorial
Intelligent Recommendation
Two-stage Mask RCNN for Tensorrt Int8 quantization
1, download and install Tensorflow == 1.13.1 2, download UFF == 0.6.5 3, download tensorrt == 7.0.0.11 4、git clone https://github.com/matterport/Mask_RCNN.gitMaskrcnn training 5, convert t...
INT8 quantization of KL dispersion (relative entropy)
We know, the smaller the relative entropy of the data of P, Q, the closer the P, Q distribution, less information with Q approximate P loss, the INT8 quantization of Ying Weida is based on this princi...
[Tensorrt] - INT8 quantization process analysis / contrast
Keywords: Tensorrt, Int8 Introduction: INT8 reasoning requires a graphics card greater than 6.1. The INT8 engine is built from 32-bit network definitions, similar to 32-bit and 16-bit engines, but the...
Tensorrt Getting Started (7) INT8 Quantization
Article catalog 0. Preface 1. sampleINT8 1.1 Example 1.2 extension reading 2. sampleINT8API 2.1 Introduction 2.2 Extended reading 3. Python Caffe MNIST INT8 0. Preface Tensort provides FP16 quantizati...

INT8 quantization principle of model acceleration (based on TensorRT)
A brief summary of model quantization: 1、The definition of quantization is to quantize network parameters from Float-32 to lower bits, such as Float-16, INT8, 1bit, etc. 2. The role of quantification:...
More Recommendation

Some quantization methods used in network model int8 quantization
1 Overview Foreword: This blog refers to the quantization methods involved in the network when doing int8 infer. The int8 training is not involved here. The quantization methods involved in this artic...
NCNN INT8 implementation
2.4 INT8 Quantization Realization - Calibration Implementation (Python) The next detailed part of the code implementation, as well as related knowledge, such as why we want to distribute SMOOTH proces...

TensorRT INT8 quantization principle and how to write a calibrator class for calibration
Go to https://blog.csdn.net/oYeZhou/article/details/106719154 At the same time, the process of using TensorRT for INT8 quantization is also sharedGitHub, Everyone is welcome to refer to. table of Cont...
Openvino 2021R1 Super Resolution Reconstruction INT8 Quantization - WAIFU2X
Next, try the excess INT8 quantization, or take the WAIFU2x model to test First of all, there is no unexpected drop into the pit ... I have installed Openvino 2021R2 in the system, I want to st...

NCNN + INT8 + YOLOV4 quantization model and real-time reasoning
NCNN + INT8 + YOLOV4 quantization model and real-time reasoning Note: This article is reprinted2 author PengTougu, two masses of computer research. I. Introduction On May 7, 2021, Tencent Yapo Lab off...