Introduction to common algorithms
First, divide and conquer
The divide-and-conquer method is the law of divide and conquer. The core idea is to say that a big problem that is difficult to solve directly is divided into two or more sub-problems according to the same concept, so that each can be broken. The smaller the scale of the problem, the easier it is to solve directly, so that the size of the sub-problem is continuously reduced until these sub-questions are simple enough to be solved, and finally the solutions of the sub-problems are combined to get the final answer to the original problem.
The application of divide and conquer is quite extensive, such as quick sorting, recursive algorithm, and large integer multiplication.
Second, recursive method
Recursion is a special kind of algorithm, which is similar to the divide and conquer method. It is to decompose a complex algorithm problem, make the scale smaller and smaller, and finally make the sub-problem easy to solve. In recursive algorithms, functions can be called not only by other functions, but also by calling their own functions.
The formal definition of recursion: a function or subroutine, defined or called by itself, is called recursion. Recursion must satisfy at least two conditions: one is a recursive process that can be executed repeatedly, and the other is an exit that can leave the recursive execution function.
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return (fib(n-1)+fib(n-2))
n = int(input('Please enter the Fibonacci sequence to calculate the first few items: '))
for i in range(n+1):
print('fib(%d)=%d' %(i,fib(i)))
Third, greed
The greedy method starts from a certain starting point and uses the greedy principle in each problem-solving step, that is, adopts the most favorable or optimal choice in the current state, continuously improves the solution, and continues to select the best in each step. Method, and gradually approaching a given target, the algorithm stops when a certain step is reached and no further progress can be made.
The idea of the greedy algorithm is to divide the problem of solving into several sub-problems, but this does not guarantee that the final solution obtained is optimal. The greedy law is easy to make decisions too early, and can only be used to satisfy the scope of feasible solutions under certain constraints. Of course, you can get the best solution for some problems.
The greedy method is often used to find the minimum spanning tree (MST), shortest path and Huffman coding of the graph.
Fourth, dynamic programming
The dynamic programming method is similar to the divide-and-conquer method. Its main practice: if the answer to a question is related to the sub-question, the big problem can be disassembled into small problems. The difference from the divide-and-conquer method is that each sub-question can be made. The answer is stored for immediate access during the next solution. This approach not only reduces the time for recalculation, but also combines these solutions into solutions to large problems. Therefore, using dynamic programming can solve the problem of double counting.
#
Output = [None]*1000 #fibonacci temporary storage area, the content is empty
def fib_DPA(n):
result = output[n]
if result == None:
if n == 0:
result = 0
elif n == 1:
result = 1
else:
result = fib_DPA(n-1) + fib_DPA(n-2)
output[n] = result
return result
n = int(input('Please enter the Fibonacci sequence to calculate the first few items: '))
for i in range(n+1):
print('fib(%d)=%d' %(i,fib_DPA(i)))
Five, enumeration method
The enumeration method, also known as the exhaustive method, is a common mathematical method. Its core idea is to enumerate the possibilities. According to the requirements of the problem, enumerate the answers to the questions one by one, or in order to solve the problems, divide the problems into limited and non-repetitive situations, enumerate the various situations one by one, and solve them, and finally reach the goal of solving the whole problem. The disadvantage of this algorithm is that it is too slow.
Six, retrospective method
Backtracking is also a kind of enumeration. For some problems, backtracking is a general algorithm that can find all (or part of) solutions while avoiding enumerating incorrect values. Once an incorrect value is found, it will not recurse to the next layer, but will go back to the previous layer to save time. It is a way to go back and go. It is characterized by finding the solution of the problem in the search process. When it is found that the solution condition is not satisfied, it traces back and tries other paths to avoid invalid search.
Intelligent Recommendation
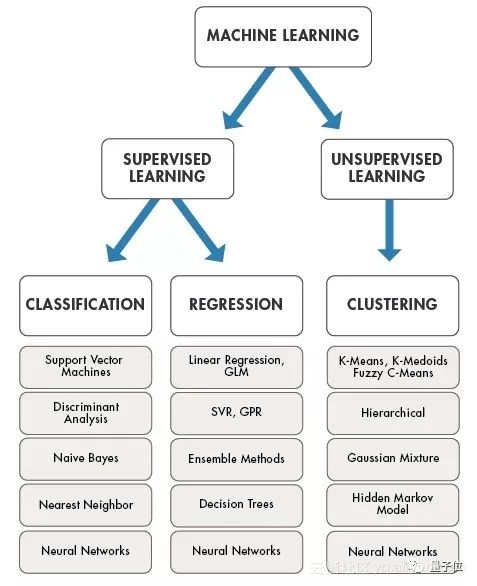
An introduction to common machine learning algorithms
This article comes from AI new media qubit (QbitAI) The so-called machine learning algorithm is a set of hypotheses used to find the optimal model. Machine learning algorithms can be divided into thre...

Introduction to the principles of common sorting algorithms
Common sorting algorithm principle study notes Bubble Sort Quick sort Insertion sort Hill sort Select sort Merge sort Base sort Heap sort Implementation of each sorting algorithm code Bubble Sort Comp...
Introduction to eight common sorting algorithms
Direct insertion sort Algorithm idea First, compare the second number with the first number. If the second number is smaller than the first number, insert the second number before the first number to ...

Introduction and implementation of common search algorithms
Common search algorithms: Sequential (linear) search Binary search/binary search Interpolation lookup Thinking analysis: Traverse the array from beginning to end, and return the array index when found...

Introduction to Map collection and common algorithms
Article Directory HashMap TreeMap Common algorithms Several ways to convert json to map Features of Map collection: * 1. Unordered * 2. Data storage by key-value pair * 3. The key is unique and the va...
More Recommendation
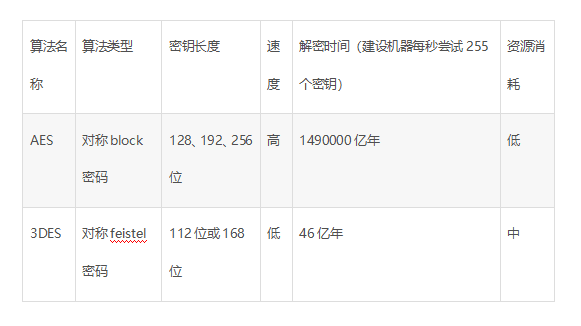
Classification and introduction of common encryption algorithms
1. Classification of encryption algorithms Does not consider decryption issues at all; Private key encryption technology: Symmetric Key Encryption: Symmetric encryption uses the same key for encryptio...
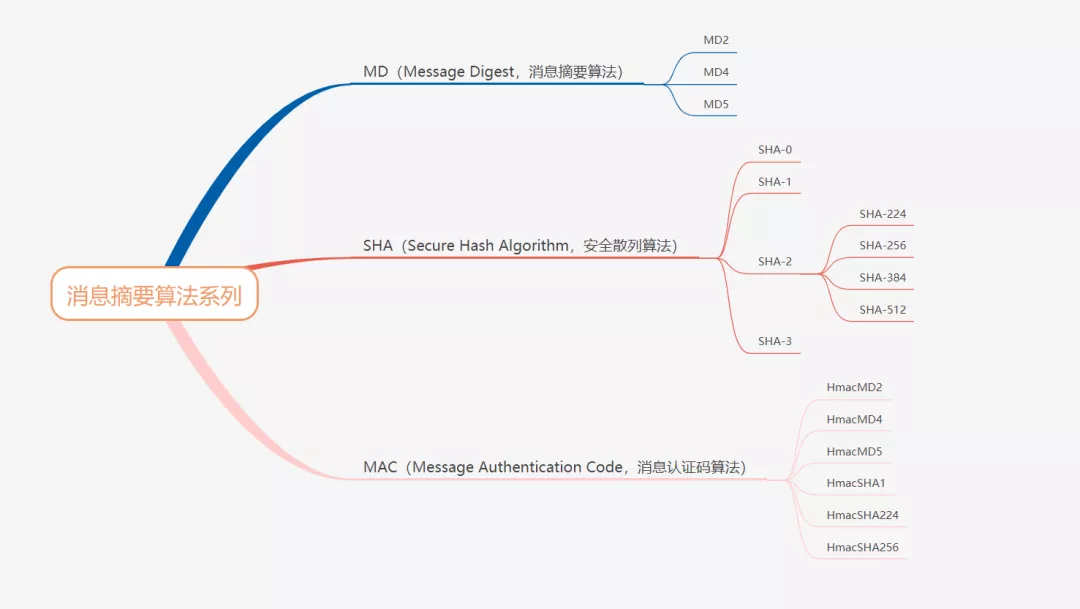
Introduction to common encryption related algorithms
Introduction to common encryption related algorithms Summary algorithm Symmetrical encryption algorithm Asymmetric plus algorithm algorithm National secret algorithm Summary algorithm: The same plain ...

Introduction to Common Data Algorithms for Blockchain
When learning blockchain in depth, it is inevitable to understand cryptography. Cryptography has been circulating for a long time and has a history of thousands of years. It has been widely used in th...

Introduction to Machine Learning -- Introduction to Common Algorithms
Introduce several concepts first: decision tree, naive Bayes, gradient descent, linear regression Decision tree Decision tree Naive Bayes Here I only think of the Bayesian probability formula, welcome...
Introduction to common encryption algorithms, as well as detailed introduction to MD5 and RSA algorithms
Introduction from Zhihu: The HASH algorithm is not the algorithm of the HASH table in the data structure class in the university. The HASH algorithm here is the basis of cryptography. MD5 and SHA are ...