Distributed storage ceph: CRUSH algorithm
tags: storage
As a distributed storage system, how to distribute data reasonably is very important. Many characteristics of the Ceph system, such as decentralization, scalability, and load balancing, are inseparable from the CRUSH data distribution algorithm it uses. After continuous practice and optimization, Ceph is recognized by everyone as one of the important backends of open source cloud storage, which is also inseparable from the advanced design of the CRUSH algorithm.
Basic characteristics of CRUSH algorithm
It is not simple to implement a data distribution algorithm for a distributed storage system. At least the following conditions need to be considered.
· Realize the random distribution of data, and can quickly index when reading.
· Able to redistribute data efficiently, and minimize data migration when equipment is added, deleted, and failed.
· "Able to reasonably control the invalid domain of data according to the physical location of the device.
· Support common data security mechanisms such as mirroring, disk arrays, erasure codes, etc.
· Support the weight distribution of different storage devices to express their capacity or performance.
The CRUSH algorithm considers the above five situations when designing. As shown in the figure below, the CRUSH algorithm obtains n random (3 in the figure) ordered positions according to the input x, namely OSD.k, and guarantees that the output for the input x is always the same under the same metadata. In other words, Ceph only needs to maintain and synchronize a small amount of metadata in the cluster, and each node can independently calculate the location of all data, and ensure that the output result is the same for the same input x. The calculation process of the CRUSH algorithm does not require any central node intervention. This decentralized design can theoretically withstand the failure of any node, reducing the adverse impact of cluster size on performance.
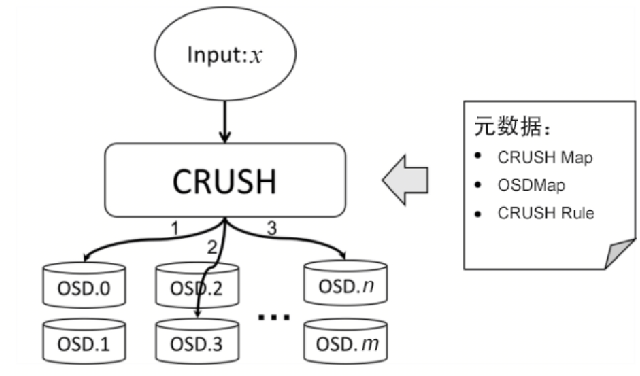
CRUSH metadata includes CRUSH Map, OSDMap and CRUSH Rule. Among them, CRUSH Map saves the location information and weight settings of all devices or OSD storage nodes in the cluster, so that the CRUSH algorithm can perceive the actual distribution and characteristics of the OSD, and the user-defined CRUSH Rule ensures that the locations selected by the algorithm can be reasonably distributed In different failure domains. OSDMap saves the runtime status of each OSD, allowing the CRUSH algorithm to sense the failure, deletion, and addition of storage nodes, minimize data migration, and improve the availability and stability of Ceph in various situations. The details of these metadata concepts and algorithms will be introduced in the follow-up content, and will also focus on the design of Ceph and CRUSH algorithms, as well as the specific usage of some CRUSH algorithms.
Device location and status in CRUSH algorithm
Before introducing the details of the CRUSH algorithm, it is necessary to introduce how CRUSH metadata maintains OSD device information. Among them, CRUSH Map mainly saves the physical organization structure of OSD, while OSDMap saves the runtime state of each OSD device. The CRUSH algorithm accesses and traverses the CRUSH Map through a series of carefully designed hash algorithms, and selects the normally operating OSD to save the data object according to user-defined rules.
1. Physical organization of CRUSH Map and equipment
CRUSH Map is essentially a directed acyclic graph (DAG), used to describe the physical organization and hierarchical structure of OSD. Its structure is shown in the figure below. All leaf nodes represent OSD devices, and all non-leaf nodes represent buckets. Buckets are divided according to levels and can define different types (CRUSH Type or Bucket Class), such as root node, rack, power supply, etc.
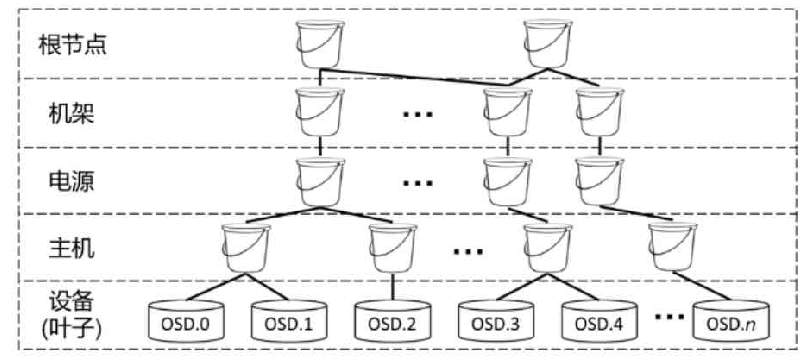
By default, Ceph will create two types of buckets, namely the root node and the host, and then put all OSD devices in the corresponding host type bucket, and then put all the host type buckets into a root node type bucket in. In more complex situations, for example, to prevent data loss due to rack network failure or power failure, users need to create the bucket type hierarchy and establish the corresponding CRUSH Map structure.
To view the CRUSH Map of the current cluster, you can use the following command:
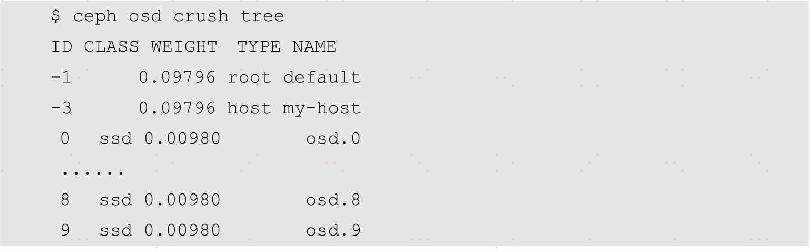
Among them, a row with a negative ID indicates a CRUSH bucket, a row with a non-negative ID indicates an OSD device, CLASS indicates a Device Class of an OSD device, and TYPE indicates a bucket type, that is, a CRUSH Type.
2.CRUSH Map Leaf
All leaf nodes in the CRUSH Map are OSD devices, and each OSD device has a name, a Device Class, and a globally unique non-negative ID in the CRUSH Map. Among them, the default Device Class has three types of hard disk drives, solid state drives and NVMe, which are used to distinguish different device types. Ceph can automatically identify the Device Class type of OSD, of course, it can also be manually created and specified by the user. Currently, Ceph maintains a Shadow CRUSH Map for each Device Class. When a Device Class is specified in the user rules, such as a solid state drive, the CRUSH algorithm will be executed based on the corresponding Shadow CRUSH Map. You can use the following command to view the Device Class and Shadow CRUSH Map:

3.CRUSH Map bucket
All non-leaf nodes in the CRUSH Map are buckets, and buckets also have a name, a bucket class, and a globally unique negative ID. Buckets belonging to the same Bucket Class are often at the same level in the CRUSH Map, and in a physical sense they often correspond to the same category of failure domains, such as hosts and racks.
As a container for storing other buckets or devices, the bucket can also define a specific list of child elements, the corresponding weight (Weight), the specific strategy of the CRUSH algorithm to select child elements, and the hash algorithm. Among them, the weight can indicate the capacity or performance of each sub-element. When expressed as a capacity, its value is in TB by default, and the specific weight can be fine-tuned according to different disk performance. The CRUSH algorithm's strategy for selecting the child elements of the bucket is also called Bucket Type. The default is the Straw method. It is related to the implementation of the CRUSH algorithm. We only need to know how different strategies are closely related to how data is redistributed, computational efficiency and weight processing , The specific details will be introduced later. The default value of the hash algorithm in the bucket is 0, which means rjenkins1, which is Robert Jenkin's Hash. Its characteristic is to ensure that even a small amount of data changes or regular data changes can cause huge changes in the hash value and make the distribution of the hash value close to uniform. At the same time, its calculation method can make good use of the calculation instructions and registers of the 32-bit or 64-bit processor to achieve higher performance. In CRUSH Map, Bucket Class and Bucket are specifically defined as follows:

4. OSDMap and device status
During operation, Ceph's Monitor will maintain a running state of all OSD devices in the OSDMap and synchronize them within the cluster. Among them, the OSD operating status is updated through the heartbeat of OSD-OSD and OSD-Monitor. Any change in the cluster status will cause the OSDMap version number (Epoch) maintained in the Monitor to increase, so that the Ceph client and OSD service can compare the version number to determine whether their Map is out of date and update it in time.
The specific state of the OSD device may be in the cluster (in) or not in the cluster (out), and normal operation (up) or abnormal operation state (down). The in, out, up, and down states of the OSD device can be combined at will, but when the OSD is in both in and down states, it means that the cluster is in an abnormal state. When the OSD is almost full, it will also be marked as full. We can query the status of OSDMap through the following commands, or manually mark the status of OSD devices:

Rules and algorithm details in CRUSH
After understanding how CRUSH Map maintains the physical organization of OSD devices, and how OSDMap maintains the runtime state of OSD devices, it is easier for us to understand how CRUSH Rule achieves a personalized data distribution strategy and the implementation of CRUSH algorithm Mechanism.
1. CRUSH Rule basis
Only knowing the location and status of the OSD device, the CRUSH algorithm still cannot determine how the data should be distributed. Due to different specific usage requirements and scenarios, users may need completely different data distribution methods, and CRUSH Rule provides a way to guide the specific execution of the CRUSH algorithm through user-defined rules. The main scenarios are as follows.
· Number of data backups: The rules need to specify the number of backups that can be supported.
· Data backup strategy: Generally speaking, multiple data copies do not need to be in order; but the erasure codes are different, and the fragments of the erasure codes need to be in order. Therefore, the CRUSH algorithm needs to know whether there is a sequence between each associated copy.
·Select the type of storage device: The rules need to be able to choose different storage device types to meet different needs, such as high-speed and expensive solid-state hard drive type devices, or low-speed, cheap hard disk drive type devices.
Determine the failure domain: In order to ensure the reliability of the entire storage cluster, the rules need to select different failure domains according to the device organization structure in the CRUSH Map, and execute the CRUSH algorithm in turn.
Ceph clusters can usually automatically generate default rules, but the default rules can only ensure that cluster data is backed up on different hosts. The actual situation is often more refined and complicated, which requires users to configure their own rules according to the invalid domain and save them in the CRUSH Map. The code is as follows:

Among them, the number of backups that the rule can support is determined by min_size and max_size, and the type determines the backup strategy to which the rule applies. When Ceph executes the CRUSH algorithm, it uses the unique ID corresponding to the ruleset to determine which rule to execute, and selects the failure domain and the specific device through the step defined in the rule.
2. CRUSH Rule step take and step emit
The first and last steps of the CRUSH Rule execution steps are step take and step emit respectively. Step take uses the bucket name to determine the selection range of the rule, which corresponds to a certain subtree in the CRUSH Map. At the same time, you can also select Device Class to determine the selected device type, such as a solid state drive or a hard drive, and the CRUSH algorithm will execute the next step choose based on the corresponding Shadow CRUSH Map. The specific definition of step take is as follows:

Step emit is very simple, which means that the step is over and the selected position is output.
3.Step choose and CRUSH algorithm principle
The intermediate step of CRUSH Rule is step choose, and its execution process corresponds to the core implementation of the CRUSH algorithm. Each step choose needs to determine a corresponding invalid domain and the number of selected sub-items in the current invalid domain. Due to different data backup strategies (such as mirroring and erasure coding), step choose also determines the arrangement strategy of the selected backup location. Its definition is as follows:

Each sub-item to be selected has its own weight value. If randomly selected according to the weight, there is no way to ensure that the same sub-item is selected every time. The essence of the CRUSH algorithm is to use a pseudo-random method to select the required sub-item, and as long as each The second input is the same as the sub-items selected by the pseudo-random method are also fixed. The specific process is as follows:
(1)、CRUSH_HASH( PG_ID, OSD_ID, r ) ===> draw
(2)、( draw &0xffff ) * osd_weight ===> osd_straw
(3)、pick up high_osd_straw
r as a constant, the first line actually uses PG_ID, OSD_ID and r together as the input of CRUSH_HASH to obtain a hexadecimal output, which is completely similar to the mapping from HASH (object name) to PG, but two more Inputs. For the same three inputs, the calculated draw value must be the same.
The CRUSH algorithm ultimately hopes to get a random number, which is the draw here, and then multiply the random number by the weight of the OSD, so as to associate the random number with the weight of the OSD, and get the actual length of each OSD. , And each lot is not the same length (very high probability), it is easy to pick the longest one. After selecting an OSD, r=r+1 repeat the above three steps to select the second OSD, and then select the specified number of OSDs in turn.
In the tree structure of the previous CRUSH Map graph, each node has its own weight, and the weight of each node is accumulated by the weight of the nodes in the next layer, so the weight of the root node root is all of the cluster The sum of OSD weights, with so many weights, we can use the crush algorithm to select layer by layer.
RULE is generally divided into three steps: take-->choose N-->emit. The Take step is responsible for selecting a root node. This root node is not necessarily root, but can also be any bucket. What choose N does is to select buckets that meet the conditions according to the weight of each bucket and each choose statement, and the selection object of the next choose is the result obtained in the previous step. Emit is to output the final result, which is equivalent to popping.
In addition, the bucket definition in the CRUSH Map can also affect the execution of the CRUSH algorithm. For example, the CRUSH algorithm also needs to consider the weight of the children in the bucket to determine their probability of being selected, and at the same time, minimize data migration when the operating state in the OSDMap changes. The specific sub-element selection algorithm is determined by the Bucket Type in the bucket definition.
The bucket definition can also determine the hash algorithm selected when the CRUSH algorithm is executed. Hash algorithms often lead to selection conflicts. Similarly, when the hash algorithm selects the OSD device, it may be found that it is marked as an abnormal operating state in the OSDMap. At this time, the CRUSH algorithm needs to have its own set of mechanisms to resolve selection conflicts and selection failures.
1) Selection method, number of choices and invalid domain
In the step configuration, you can define the bucket class selected in the current step, that is, the invalid domain, and the specific number n selected. For example, let the data backup be distributed in different racks, the code is as follows:

Or let the data be distributed in two hosts under two power supplies, the code is as follows:

Among them, when the value of the selected number n is 0, it means that the bucket with the same number of backups is selected; when the value of n is negative, it means the number of backups minus n buckets; when the value of n is positive, that is Select n buckets.
Chooseleaf can be regarded as a shorthand for choose, it will continue to recurse after selecting the specified Bucket Class until the OSD device is selected. For example, the rule to distribute data backups in different racks can also be written as:

2) Choose a backup strategy: firstn and indep
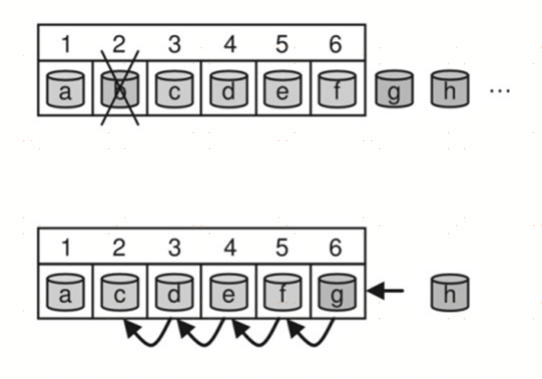
The selection strategy of the CRUSH algorithm is mainly related to the backup method. Firstn corresponds to backing up data in a mirroring manner. The main feature of mirror backup is that there is no sequence between data backups, that is, when the main backup fails, any subordinate backup can be converted to the main backup for data read/write operations. Its internal implementation can be understood as the CRUSH algorithm maintains a device queue selected based on the hash algorithm. When a device is marked as invalid in the OSDMap, the backup on the device will also be considered invalid. This device will be removed from this virtual queue, and subsequent devices will serve as a substitute. The literal meaning of firstn is to select the first n devices in the virtual queue to save data. This design can ensure that the amount of data migration can be minimized when the device fails and recovers. The firstn strategy is shown in the figure below.
Indep corresponds to backing up data in an erasure code. The data block and check block of the erasure code are in order, which means that it cannot replace the failed device like firstn, which will cause the relative position of the subsequent backup device to change. Moreover, after a temporary failure of multiple devices, there is no guarantee that the devices will remain in their original positions after restoration, which will lead to unnecessary data migration. Indep solves this problem by maintaining an independent (Independent) virtual queue for each backup location. In this way, the failure of any device will not affect the normal operation of other devices; and when the failed device resumes operation, it can be guaranteed to be in its original position, reducing the cost of data migration. The indep strategy is shown in the figure below.
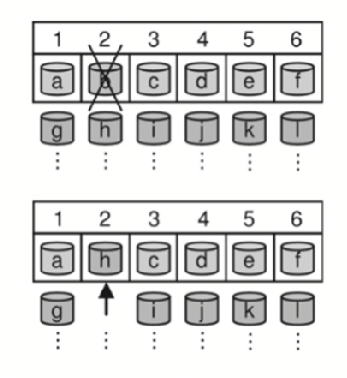
The virtual queue is realized by calculating the index value. To put it simply, for the firstn strategy, when the second device b (index value 2) fails, the second mirror position will re-point to the device with the index value of 2+1, that is, the rth mirror position will point to the index value It is a device of r+f, where f is the number of failed devices in the previous sequence. For the indep strategy, as shown in Figure 7-17, when the second device b fails, the second mirror position will point to the device h with an index value of 2+1×6, that is, the rth mirror position It will point to the device with the index value of r+f×n, where f is the device failure count and n is the total number of backups.
3) The way to select the child elements of the bucket: Bucket Type
After the CRUSH algorithm determines the final selected index value, it does not directly select the sub-bucket or sub-device from the corresponding bucket according to the index value. Instead, it provides multiple options for users to configure according to different situations. The selection algorithm of sub-elements is configured by Bucket Type. There are 5 types: Uniform, List, Tree, Straw and Straw2. They each have different characteristics, which can be weighed in the three dimensions of algorithm complexity, support for the increase and decrease of cluster devices, and support for device weights.
According to the algorithm implementation of Bucket Type, the selection algorithm of sub-elements can be divided into three categories. The first is Uniform, which assumes that the equipment capacity of the entire cluster is uniform and the number of equipment changes very little. It does not care about the weights configured in the sub-devices, and directly distributes the data to the cluster through the hash algorithm, so it also has the fastest calculation speed O(1), but its application scenarios are extremely limited.
The second is the divide and conquer algorithm. List will check each sub-element one by one, and determine the probability of selecting the corresponding sub-element according to the weight. It has O(n) complexity. The advantage is that it can minimize data migration when the cluster size continues to increase, but it will be removed when the old node is removed Lead to redistribution of data. Tree uses a binary search tree to make the probability of searching for each child element consistent with the weight. It has O(logn) algorithm complexity, and can better deal with the increase or decrease of cluster size. However, the Tree algorithm still has flaws in the Ceph implementation and is no longer recommended.
The problem with the divide-and-conquer algorithm is that the selection probability of each sub-element is globally related, so the addition, deletion, and weight change of sub-elements will affect the global data distribution to a certain extent, and the amount of data migration caused by this is not the most Excellent. The emergence of the third type of algorithm is to solve these problems. Straw will make all sub-elements compete with each other independently, similar to the lottery mechanism, let the lottery length of the sub-elements be based on the weight distribution, and introduce a certain degree of pseudo-randomness, so as to solve the problems caused by the divide and conquer algorithm. Straw's algorithm complexity is O(n), which will take a little longer compared to List, but it is still acceptable and has even become the default bucket type configuration. However, Straw has not been able to completely solve the problem of the minimum amount of data migration, because the calculation of the signature length of the sub-elements still depends on the weights of other sub-elements. The proposal of Straw2 solves the problem of Straw. It does not depend on the status of other sub-elements when calculating the sign length of the sub-elements, and guarantees the data score.
The cloth follows the weight distribution and has the best performance when the cluster size changes.
Application of CRUSH Algorithm in Ceph
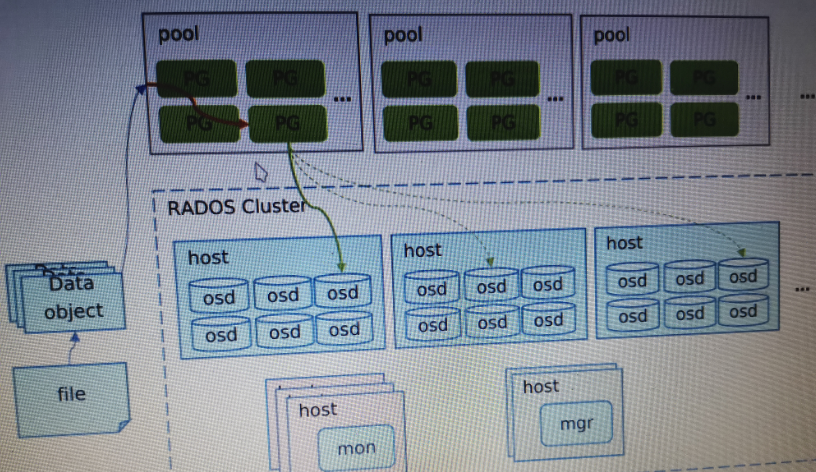
Ceph does not directly use the CRUSH algorithm to map the data objects to the OSD one by one, which will be very complicated and inefficient. Moreover, Ceph users don't need to know how the actual CRUSH algorithm works, they only need to care about where the data is stored. Ceph hides the complexity of the CRUSH algorithm through two logical concepts, namely storage pool and PG, and provides users with an intuitive object storage interface, namely RADOS.
1. Storage pool
The storage pool in Ceph is created by the administrator to isolate and store the logical structure of data. Different storage pools can be associated with different CRUSH rules, specify different backup quantities, store data in mirroring or erasure coding, or specify different access rights and compression methods. Users can also take snapshots in units of storage pools, and even create upper-level applications, such as block storage, file storage, and object storage. As for how the storage pool itself guarantees data security and distribution, this is determined by the CRUSH rules associated with the storage pool. Users do not need to understand these details in depth, just remember the name of the data, and select the appropriate storage pool in RADOS. Perform read/write operations in the The command to create a storage pool is as follows:

2.PG
The number of PGs needs to be specified when the storage pool is created. PG is a logical concept for storing actual data objects in a storage pool. Data objects in Ceph are always uniquely stored in a PG in a storage pool, or the storage pool manages and saves all user data objects by maintaining a fixed number of PGs.
Unlike the storage pool concept, the user cannot determine which PG the object is stored in. This is calculated by Ceph itself. The meaning of PG is to provide a layer of abstraction for the storage space. It conceptually corresponds to the virtual address space of the operating system, and isolates the logical location of the data object from the details of which OSD device it is stored in. In this way, the virtual space of each storage pool can be isolated from each other, and the physical space of the OSD device can be better utilized and maintained. The specific implementation is shown in the following figure. Ceph first distributes the data objects to different logical PGs through the hash algorithm, and then distributes the PGs to all OSD devices reasonably by the CRUSH algorithm. In other words, the CRUSH algorithm actually determines the data distribution and controls the disaster tolerance domain in units of PGs rather than data objects, and logically a group of PGs form a continuous virtual space to store data objects in the storage pool.
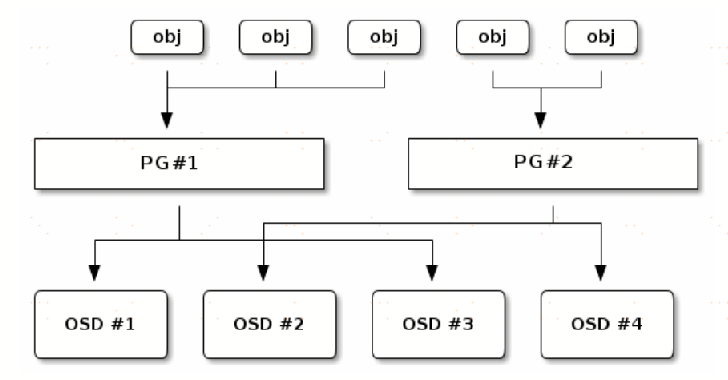
The emergence of the PG concept has increased the complexity of the overall implementation of Ceph, but its advantages are also obvious. The number of data objects that can be saved in Ceph is very large. The data objects are grouped in the unit of PG, and large blocks of data are also managed in the unit of PG, such as performing operations such as data recovery, verification, and fault handling. Maintenance overhead will not increase significantly as the number of data objects increases. This can reduce the computational resource overhead of large-scale data volume in the design, including CPU, memory, and network resources.
Although fewer PGs can reduce resource overhead and improve processing performance, too few PGs can easily lead to uneven data distribution and worse disaster tolerance performance. So how to configure the number of PGs in the storage pool is of great significance to the entire Ceph cluster. Generally speaking, when 50 to 100 PGs are maintained on each OSD, the cluster can have a more balanced performance. However, it is often difficult to calculate specific values under complex storage pool configurations. Fortunately, the Ceph community provides the pgcalc tool to assist in configuring all PG numbers.
Intelligent Recommendation
ceph distributed storage deployment
** 1. Basic environment configuration** Create three CentOS 7 system virtual machines (according to specific circumstances), and modify the hostname to be node1, node2 and node3. Each ceph node needs ...
Ceph distributed storage learning
History of storage equipment The use of storage in an enterprise has been continuously developing and iterating according to its functions and usage scenarios. It can be roughly divided into four stag...
Distributed storage ceph: Qos
QoS originated in network communication, which means that a communication network can use various basic technologies to provide better service capabilities for specific applications. Simply put, it is...
Distributed storage ceph: architecture
The target application scenario initially targeted by Ceph is a large-scale, distributed storage system. Ceph needs to adapt well to the dynamic characteristics of such a large-scale storage system. &...
Introduction to ceph distributed storage
Article Directory Distributed storage RADOS components 1. Monitors 2. Managers 3. Ceph OSDs 4. MDSs Data abstraction interface (client middle layer) CEPH FILESYSTEM CEPH BLOCK DEVICE CEPH OBJECT GATEW...
More Recommendation
Distributed storage-ceph
Introduction to ceph Ceph is a unified, distributed file system () designed for excellent performance, reliability and scalability. The unified embodiment of ceph can provide file system, block sto...
Deploy Ceph distributed storage
2.1 Problem Deploy Ceph distributed storage to achieve the following effects: 2.2 Scheme The experiment topology is shown in Figure-2. Please configure the environment before doing specific experiment...
Distributed storage Ceph technology
Introduction to Ceph Ceph architecture Basic components of Ceph Ceph structure Ceph storage types and application scenarios Block storage File storage Object storage How Ceph works No matter wh...
Distributed storage----------CEPH application
** CEPH application ** 1. RBD block storage: 2. cephFS: understand, it is not recommended to use it in a production environment because it is not yet mature 3. Object storage: understand, use Amazon's...
Distributed storage----------CEPH build
** Distributed storage The storage resources in the system management team are not necessarily directly connected to the local node, but connected to the node through a computer network. The design of...