FastText
FastText
Label (space separated): natural language processing
FastText
FastText paper link
Review
FastText is not a special kind of institution, but an idea that is to get results faster.
FastText(pytorch) for text categorization
class FastText(BasicModule):
def __init__(self, config, vectors=None):
super(FastText, self).__init__()
self.config = config
self.embedding = nn.Embedding(config.vocab_size, config.embedding_dim)
if vectors is not None:
self.embedding.weight.data.copy_(vectors) ## Embed the word vector into self.embedding
self.pre = nn.Sequential(
## This is equivalent to converting the original 300-dimensional vector into 600-dimensional
nn.Linear(config.embedding_dim, config.embedding_dim * 2),
nn.BatchNorm1d(config.embedding_dim * 2),
nn.ReLU(True)
)
self.fc = nn.Sequential(
## Here we will convert the vector of 600 dimensions into 19 dimensions, that is, the dimension transformed into the desired y (target value) by two linear layers. The following line is the first linear layer.
nn.Linear(config.embedding_dim * 2, config.linear_hidden_size),
nn.BatchNorm1d(config.linear_hidden_size),
nn.ReLU(inplace=True),
## Here is the second linear layer
nn.Linear(config.linear_hidden_size, config.label_size)
)
def forward(self, sentence):
embed = self.embedding(sentence) # seq * batch * emb 2000 * 64 * 300 ## Every sentence here is 64 sentences, 2000 words per sentence, so the dimension of the sentence is 2000*64
embed_size = embed.size() ## 2000 * 64 * 300
embed.contiguous().view(-1, self.config.embedding_dim) # 128000 * 300 This is equivalent to splicing every word in every sentence in the batch, so 12800 is like this.
out = self.pre(embed.contiguous().view(-1, self.config.embedding_dim)).view(embed_size[0], embed_size[1], -1)
mean_out = torch.mean(out, dim=0).squeeze() # batch * 2emb 64 * 600 ## This is equivalent to averaging each sentence of 2000 length
logit = self.fc(mean_out)
return logit
Intelligent Recommendation
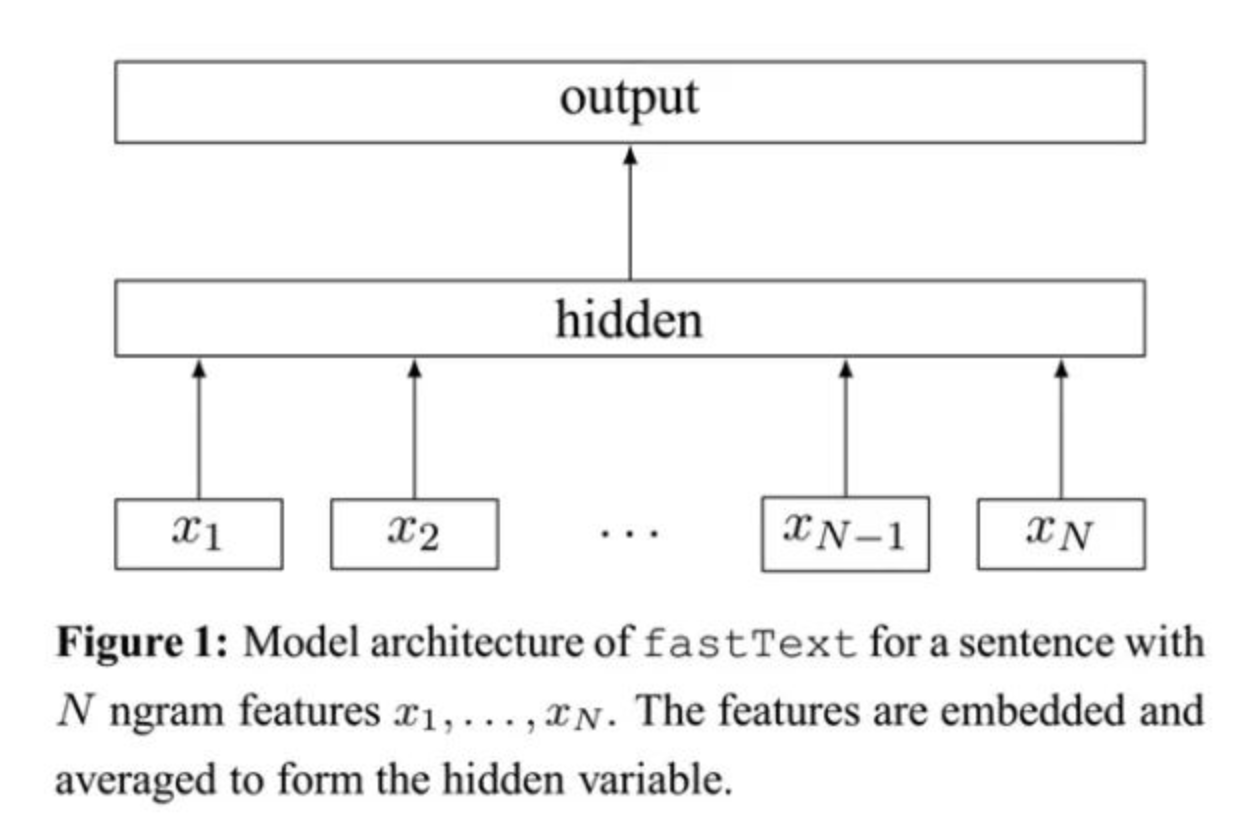
principle of fastText
table of Contents fastTest basic structure fastText advantage fastText principle Model architecture Hierarchical softmax N-gram features of fastText Comparison of FastText word vector and word2vec&par...

fastText principle
model structure of fastText x 1 , x 2 , . . . , x N − 1 , x N x_1,x_2,...,x_{N−1},x_N x1,x2,...,xN−1,xNRepresents the n-gram vector in a text, and each feature is the average of ...
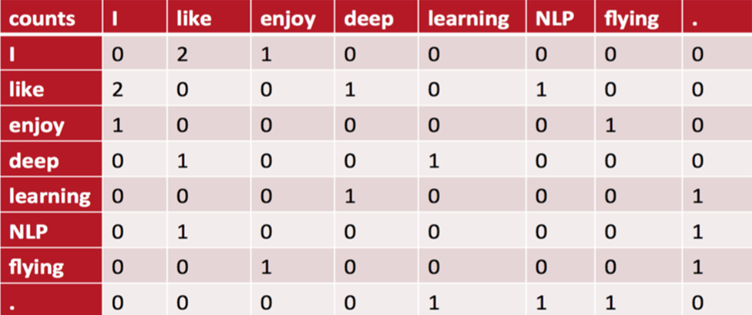
Glove and Fasttext
1.Glove Glove is a word encoding algorithm that uses word and word co-occurrence information. To understand glove, you first need to know the co-occurrence frequency matrix. Now our corpus includes th...
Train with fasttext
Train with fasttext Download fasttext Compile and install Use fasttext Transform data Use and test Data download Download fasttext Official website: https://github.com/facebookresearch/fastText Compil...
fastText algorithm
1. Introduction 1.1: fastText background Fasttext is a word vector and text classification tool open sourced by Facebook. It was open sourced in 2016. The typical application scenario is "supervi...
More Recommendation
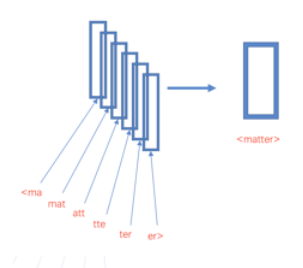
FastText understanding
background fastText is similar to word2vec. This model can be used to train word embedding and text classification. The model input is all the words and n-gram features of the text, weighted by the in...
nlp fasttext
fasttext N-Gram implementation model FastText is used for words vector and text classification, using a word bag and N-GRAM bag temple N-Gram implementation N-gram and cbow are very similar to the per...
FastText learning
1.FastText Introduction FastText is a word that represents learning and text classification. Advantages: On the standard multi-core CPU, the word vector of the word level spending can be trained withi...

NLP - fastText
Articles directory About FastText Installation & compilation Compile (recommendation) with make (recommendation) Compile with CMAKE Use PIP installation Example 1. Word representation learning 2. ...

FastText ⭐ installed under windows - [FastText]
1. Recommends Anaconda installation is recommended in advance 2. How to Install Direct use pip install fasttext I tested is not enough, you must download the installation package download link : https...