Introduction to several common GC algorithms
This article is mainly about the commonly used GC algorithm (Reference counting、Mark-sweep、Replication algorithm、Mark-sweep algorithm) Make relevant explanations and give a brief introduction to relevant knowledge.
1. What is a heap?
Heap refers to the memory space used to store objects dynamically (that is, when executing programs).And this object, inIn object-oriented programming, it refers to "things with attributes and behavior", However inIn the GC world, objects represent "a collection of data used by applications". Specific to the Java heap, it is a memory area shared by all threads and is created when the virtual machine is started. The sole purpose of this memory area is to store object instances, where almost all object instances are allocated memory. (The object instance here can be understood as the aforementioned object, because not only Java has automatic GC, but also Python, JavaScript and other languages, so in a broad sense, the object is a better expression, of course, Java array is also allocated On the heap).
Second, the evaluation criteria of the GC algorithm
The evaluation criteria of the GC algorithm are mainly the following 4 points:
1. Throughput: The processing capacity per unit time.
2. Maximum pause time: Time required to suspend program execution due to GC execution.
3. Heap usage efficiency: Fish and bear's paws can't have both. Heap utilization efficiency and throughput, and maximum pause time cannot be satisfied at the same time. That is, the larger the available heap, the faster the GC runs; on the contrary, if you want to use the limited heap, the longer the GC takes.
4. Locality of access: In the hierarchical structure of memory, we know that the more high-speed access memory capacity will be smaller (for details, please refer to the memory article I wrote). Due to the locality principle of the program, putting frequently used data closer to the heap can improve the efficiency of the program.
3. Accessibility
The so-called reachability is to use a series of objects called "GC Roots" as the starting point, and start searching downward from these nodes. The path that the search takes is called a reference chain. When an object is connected to GC Roots without any reference chain ( In the words of graph theory, when GC Roots reach this object is unreachable, it means that this object is not available. As shown in the figure below, ABC is reachable and DE is unreachable.

What about GC Roots? Taking Java as an example, there are the following:
1. Objects referenced in the stack (local variable table in the stack frame).
2. Static members in the method area.
3. Objects (global variables) referenced by constants in the method area.
4. The object referenced by JNI (general Native method) in the local method stack.
Note: The first and fourth types refer to the local variable table of the method. The second expression means more clearly. The third type mainly refers to the constant value declared as final.
Four, reference counting method
1. What is reference counting?
The so-called reference counting method is to give each object a reference counter. Whenever there is a reference to it, the counter will increase by 1. When the reference is invalid, the value of the counter will decrease by 1. The value of the counter is 0 at any time. The object cannot be used anymore.
This reference counting method is not used by Java, but Python does use it. And the most primitive reference counting method does not use GC Roots.
2. Advantages
<1> Instant garbage collection: In this method, each object always knows whether it has been referenced. When the value of the reference is 0, the object can immediately link itself to the free list as free space.
<2> The maximum pause time is short.
<3> No need to look along the pointer
3. Disadvantages
<1> Counter value increase and decrease processing is very heavy
<2> The calculator needs a lot of space.
<3> Implementation is cumbersome.
<4> Circular references cannot be recovered.
Five, mark-clear algorithm
1. What is a mark-and-sweep algorithm?
The algorithm is divided into two stages, marking and clearing. Marking is the stage of marking all active objects; clearing is the stage of recycling objects that have not been marked. As shown below.

-
advantage
<1> Simple implementation
<2>Compatible with conservative GC algorithm (conservative GC will be introduced later)
3. Disadvantages
<1> Fragmentation: As shown in the above figure, the refined blocks will be generated during the recycling process. To the back, even if the total size of the blocks in the heap is enough, but because the blocks are too small to allocate .
<2> Allocation speed: Because the blocks are not continuous, each block must traverse the free linked list to find a sufficiently large block, resulting in a waste of time.
<3> Not compatible with copy-on-write technology: the so-called copy-on-write is when fork, the memory space is only referenced and not copied, only when the data of the process changes, the data will be copied to the memory space of the process. In this way, when the memory data in the two processes are the same, a lot of memory space can be saved. For the mark-clear algorithm, each of its objects has a flag bit to indicate whether it is marked. Each time the mark-clear algorithm is run, the referenced object will be marked. This only changes the mark bit. , It will also become the change of the object data, which leads to the copy process of copy-on-write, which is contrary to the original intention of copy-on-write.
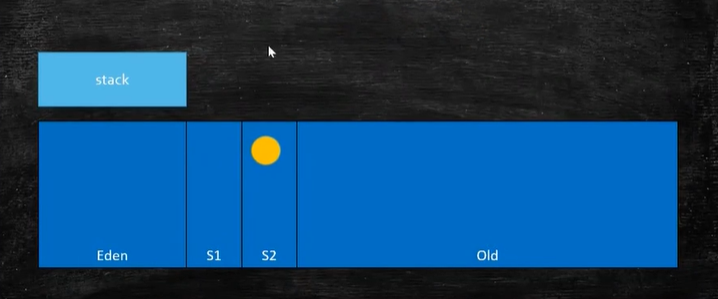
Six, copy algorithm
1. What is the replication algorithm?
The replication algorithm is to divide the memory space into two blocks according to capacity. When this piece of memory is used up, copy the surviving objects to another piece, and then clean up the used piece at a time. In this way, each half of the memory is reclaimed. When allocating memory, there is no need to consider complicated situations such as memory fragmentation. Just move the pointer on the top of the heap and allocate memory in order, which is simple to implement and efficient to run.

-
advantage
<1>Excellent throughput.
<2> High-speed distribution can be achieved: the replication algorithm does not use idle linked lists. This is because the partition is a continuous memory space. Therefore, to call the size of the partition, only the size of the partition is not smaller than the requested size, and the pointer can be allocated.
<3> Fragmentation will not occur.
<4> Compatible with cache.
3. Disadvantages
<1>Inefficient use of the heap.
<2> Not conservative GC algorithm.
<3> Call the function recursively.
Seven, mark-compression algorithm
1. What is the mark-compression algorithm?
The marking-compression algorithm is similar to the marking-cleaning algorithm, except that the next step is to move all surviving objects to one end, and then directly clear the memory beyond the end boundary.

-
Pros and cons
The algorithm can effectively use the heap, but compression requires more time cost.
8. Conservative GC and accurate GC
1. Conservative GC
The so-called conservative GC is "a GC that cannot recognize pointers and non-pointers."
For registers, call stacks, and global variable spaces, they are all ambiguous roots. For example, in the call stack, the local variables and parameter values in the function are loaded. Local variables, such as int and double in C, are non-pointers, but there will also be pointers like void*.
How does a conservative GC check for ambiguous roots? 1. Is the value properly aligned? (In the case of 32-bit CPU, it is a multiple of 4) 2. Is it pointing to the heap? 3. Does it point to the beginning of the object? Of course, these are just basic inspection items.
The above inspection method will recognize some non-pointers as pointers. For example, a value and an address are equal to each other. At this time, that value can also be recognized as a pointer.
The advantage of conservative GC is that the language processing program does not depend on GC. Disadvantages are the cost of identifying pointers and non-pointers, incorrect identification of pointers will compress the heap, and limited GC algorithms can be used. For example, the GC replication algorithm cannot be used because it may rewrite non-pointers.
2. Accurate GC
Accurate GC can correctly identify pointer and non-pointer GC. The correct root creation method depends on the implementation of the language processing program. We can do this by labeling, not using registers and stacks as roots.
The advantage is that it can fully recognize the pointer and can use the copy algorithm and other algorithms that need to move the object. But when creating an accurate GC, the language processing program must provide some support for the GC, and creating the correct root must pay a certain price.
In fact, the implementation of our garbage collector is not just a kind of recycling algorithm, but a combination of several, especially the generation algorithm, which we will introduce in detail later.
references
"In-depth understanding of the Java Virtual Machine"
"Algorithm and Implementation of Garbage Collection"
https://www.zhihu.com/question/60103311
Intelligent Recommendation
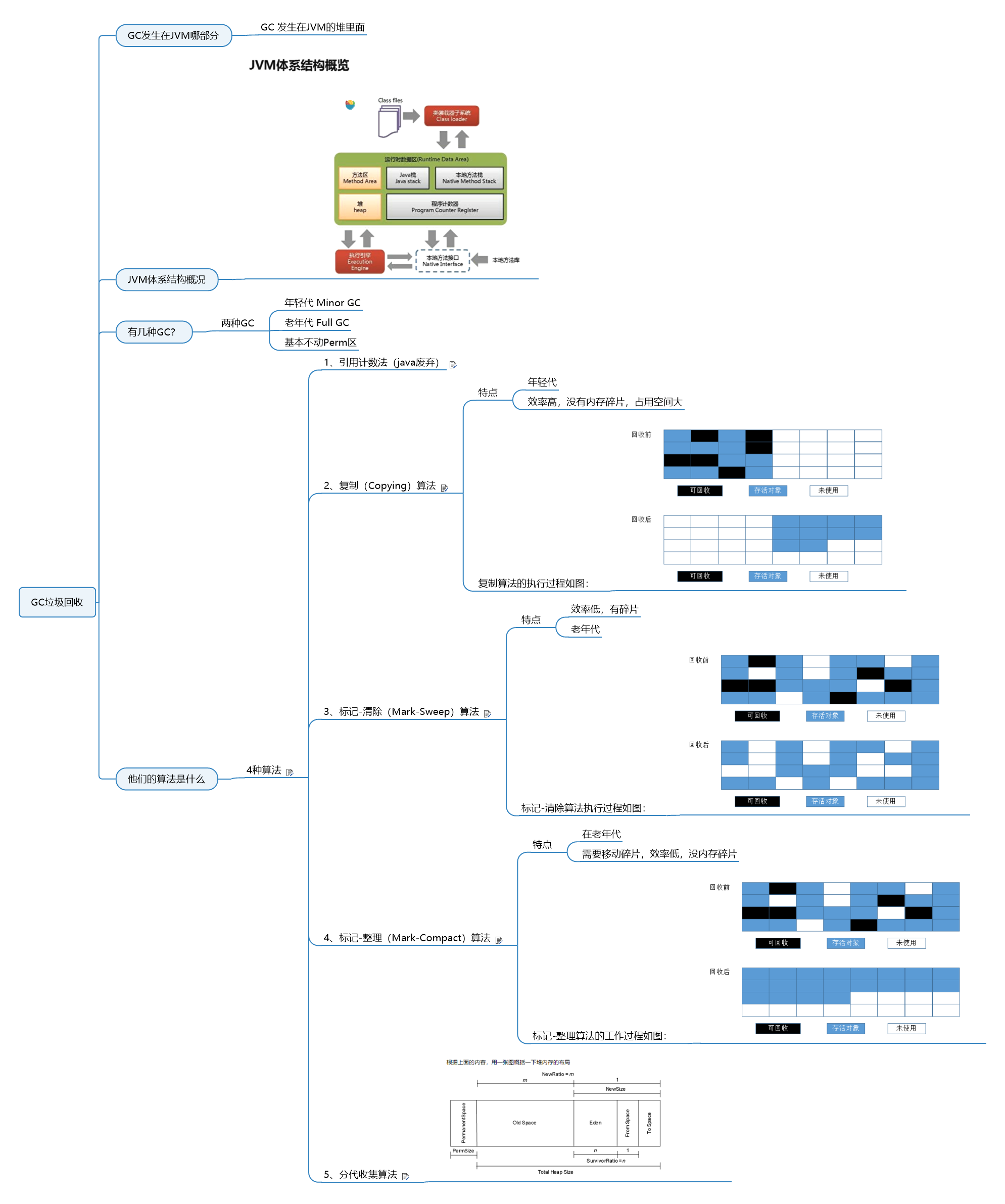
Where does GC occur in the JVM? There are several types of GC, and what are their algorithms?
Where does GC occur in the JVM? There are several types of GC, and what are their algorithms? Mind map: Where does GC occur in the JVM GC occurs in the heap of the JVM Overview of JVM architecture How...
Common GC algorithms, common garbage collectors
How does the JVM determine that the object can be recycled? 1. The object is not referenced 2. An uncaught exception occurred in the scope 3. The program is executed normally in the scope 4. The progr...
Introduction to several algorithms of Nginx
First, Nginx load balancing algorithm First, polling (default) Each request is assigned to a different back-end server one by one in chronological order. If the back-end server is down, it can be auto...
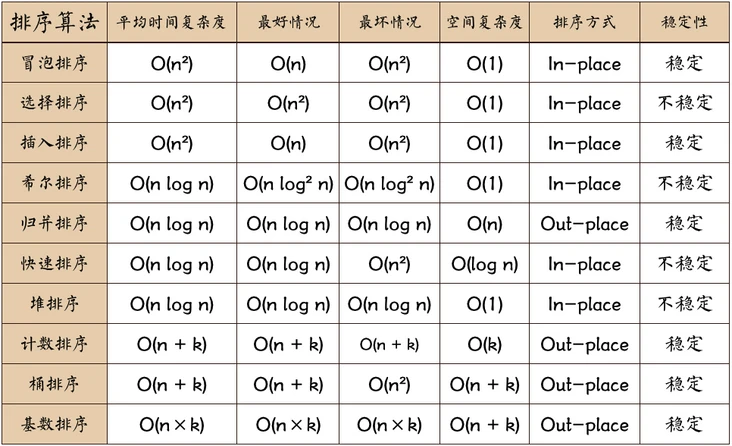
Introduction of several sort algorithms
Foreword Sort algorithm evaluation criteria time complexity One of the total execution of an algorithm statement is a function of the problem N, records F (n), N as the scale of the problem. The total...

Several common sorting algorithms
Generally, it is rare to write algorithms to sort, implement corresponding interfaces, specify sorting rules, and rich functions help to complete the sorting requirements. However, it is still necessa...
More Recommendation
Several OPENCV common algorithms
1, commonly used algorithms to find the boundary 2, find the smallest surrounding circle in the point 3. The smallest rectangle containing points 4. A positive rectangle parallel to the four sides 5. ...
Several common algorithms of JS
First, bubble sorting 1.1 Bubble Sorting Principle 1. Compare the two adjacent elements. If the previous one is larger than the latter one, the position is exchanged. 2. The last element in the first ...
Several common encryption algorithms
Here are a few common methods involved in the tool approach. 1. Base64 encryption algorithm The Base64 encryption algorithm is one of the most common encoding methods for transmitting 8-bit byte code ...
Several algorithms common in Unity
using System.Collections; using System.Collections.Generic; using UnityEngine; //The sorting algorithms commonly used in programming: bubble sorting, sorting, insert sorting, quick sorting, etc. publi...
Several common search algorithms
table of Contents Breadth-first search (BFS) Depth-first search (DFS) Hill Climbing Best-first search strategy Backtracking Branch-and-bound Search Algorithm A* algorithm Breadth-first search (...