Introduction to machine learning and common algorithms
concept
What is machine learning?
Machine learning is a literal translation of the English name Machine Learning (ML). Machine learning involves many disciplines such as probability theory, statistics, approximation theory, convex analysis, and algorithm complexity theory. Specializing in how computers simulate or implement human learning behaviors to acquire new knowledge or skills and reorganize existing knowledge structures to continuously improve their performance. It is the core of artificial intelligence, and it is the fundamental way to make computers intelligent. Its application spans all fields of artificial intelligence. It mainly uses induction, synthesis rather than deduction.
Compared to traditional computer work, we give it a bunch of instructions, and then it can be executed step by step according to this instruction. Machine learning simply doesn't accept the instructions you type. Instead, it only accepts the data you type! That is, it has the ability to handle things in our sense.
History of machine learning
Machine learning is a relatively young branch of artificial intelligence research, and its development process can be roughly divided into four periods.
The first phase was in the mid-1950s to the mid-1960s and was a period of enthusiasm.
The second phase was in the mid-1960s to the mid-1970s and was called the cool period of machine learning.
The third phase was from the mid-1970s to the mid-1980s, known as the revival period.
The latest phase of machine learning began in 1986. The important aspects of machine learning entering the new phase are as follows:
(1) Machine learning has become a new edge discipline and forms a course in colleges and universities. It combines applied psychology, biology and neurophysiology as well as mathematics, automation and computer science to form the basis of machine learning theory.
(2) Combining various learning methods, research on various forms of integrated learning systems that complement each other is emerging. In particular, the coupling of learning symbol learning can better address the problem of acquisition and refinement of knowledge and skills in continuous signal processing.
(3) A unified view of the fundamental issues of machine learning and artificial intelligence is taking shape. For example, the combination of learning and problem solving, and knowledge representation for learning, led to the block learning of the general intelligent system SOAR. The case-based approach combining analog learning with problem solving has become an important direction of empirical learning.
(4) The range of applications of various learning methods has been expanding, and some have formed commodities. Knowledge acquisition tools for inductive learning have been widely used in diagnostic subtype expert systems. Connected learning is dominant in acoustic image recognition. Analytical learning has been used to design integrated expert systems. Genetic algorithm and reinforcement learning have a good application prospect in engineering control. Neural network connection learning coupled with the symbol system will play a role in enterprise intelligent management and intelligent robot motion planning.
(5) Academic activities related to machine learning are unprecedentedly active. In addition to the annual machine learning seminars, there are computer learning theory conferences and genetic algorithm conferences.
Range of machine learning
Machine learning has deep links with pattern recognition, statistical learning, data mining, computer vision, speech recognition, and natural language processing. In terms of scope, machine learning is similar to pattern recognition, statistical learning, and data mining. At the same time, the combination of machine learning and processing techniques in other fields forms an interdisciplinary subject such as computer vision, speech recognition, and natural language processing. Therefore, in general, data mining can be equivalent to machine learning. At the same time, what we usually call machine learning applications should be universal, not only limited to structured data, but also to applications such as images and audio.
Pattern recognition
Pattern recognition = machine learning. The main difference between the two is that the former is a concept developed from the industrial world, while the latter is mainly derived from computer science. In the famous book "Pattern Recognition And Machine Learning", Christopher M. Bishop said at the beginning that "pattern recognition comes from industry, and machine learning comes from computer science. However, activities in them can be seen." For the two aspects of the same field, and in the past 10 years, they have made great progress."
Data mining
Data mining = machine learning + database, remember that the last semester of the university opened a course of data mining, what is data mining, is to mine useful data from massive data, in fact, in a sense and big data The analysis is very similar. Data mining is often associated with computer science and achieves these goals through statistics, online analytical processing, intelligence retrieval, machine learning, expert systems (reliant on past rules of thumb), and pattern recognition.
Statistical learning
Statistical learning is approximately equal to machine learning. Statistical learning is a discipline that is highly overlapping with machine learning. Because most of the methods in machine learning come from statistics, it can even be argued that the development of statistics promotes the prosperity of machine learning. For example, the famous support vector machine algorithm is derived from the statistics department. However, to some extent, there is a difference between the two. The difference lies in the fact that statistical learners focus on the development and optimization of statistical models, and on mathematics, while machine learners are more concerned with solving problems and practicing. Machine learning researchers will focus on improving the efficiency and accuracy of learning algorithms on a computer.
Computer vision
Computer vision = image processing + machine learning. Image processing techniques are used to process images into inputs suitable for entry into machine learning models, and machine learning is responsible for identifying relevant patterns from images. With the development of deep learning in the new field of machine learning, the effect of computer image recognition has been greatly promoted, so the future development of computer vision industry is immeasurable.
Speech Recognition
Speech recognition = speech processing + machine learning. Speech recognition is a combination of audio processing technology and machine learning. Speech recognition technology is generally not used alone, and generally incorporates related techniques of natural language processing. The current related applications include Apple's voice assistant siri, Xunfei and many other domestic technology companies and institutions.
Natural language processing
Natural language processing = text processing + machine learning. Natural language processing technology is primarily an area where machines understand human language. In the natural language processing technology, a lot of techniques related to the compilation principle are used, such as lexical analysis, grammar analysis, etc. In addition, in understanding this level, techniques such as semantic understanding and machine learning are used.
Machine learning algorithm
Supervised learning
The supervised learning algorithm includes a target variable (dependent variable) and a predictor (argument) used to predict the target variable. Through these variables we can build a model so that for a known predictor value, we can get the corresponding target variable value. This model is repeatedly trained until it reaches a predetermined accuracy on the training data set. The algorithms that belong to supervised learning are: regression model, decision tree, random forest, K proximity algorithm, logistic regression, etc.
Unsupervised learning
Unlike supervised learning, there is no target variable that we need to predict or estimate in unsupervised learning. Unsupervised learning is used to classify the overall object. It is widely used to classify customers based on a certain indicator. The algorithms belonging to unsupervised learning are: association rules, K-means clustering algorithms, and so on.
Reinforcement learning
This algorithm can train the program to make a decision. The program tries all possible actions in a given situation, recording the results of the different actions and trying to find the best one to make the decision. There is a Markov decision process for this type of algorithm.
Common algorithm
Common machine learning algorithm
The following are the most commonly used machine learning algorithms, and most of the data problems can be solved by them:
1. Linear Regression
2. Logistic Regression
3. Decision Tree
4. Support Vector Machine (SVM)
5. Naive Bayes
6.K Proximity Algorithm (KNN)
7.K-means algorithm (K-means)
8. Random Forest (Random Forest)
9. Dimensionality Reduction Algorithms
10.GradientBoost and Adaboost algorithms
Machine learning classification
Classification based on learning strategies
Learning strategy refers to the reasoning strategy adopted by the system in the learning process. A learning system is always composed of two parts: learning and environment. Information is provided by the environment (such as a book or teacher), and the learning part is transformed into information, memorized in an understandable form, and useful information is obtained from it. In the learning process, the less reasoning the student (learning part) uses, the more he relies on the teacher (environment) and the more burden the teacher has. The classification criteria of learning strategies are classified according to the degree of reasoning and difficulty that students need to achieve information conversion. From simple to complex, the order from small to large is divided into the following six basic types:
1) Mechanical learning (Rote learning)
Learners do not need any reasoning or other knowledge transfer to directly absorb the information provided by the environment. Such as Samuel's checkers program, Newell and Simon's LT system. The main consideration of this type of learning system is how to index the stored knowledge and use it. The systematic learning method is to learn directly through pre-programmed and constructed programs. The learner does not do any work, or learns by directly receiving the established facts and data, and does not make any reasoning about the input information.
2) Learning from instruction or Learning by being told
Students obtain information from the environment (teachers or other sources of information such as textbooks, etc.), transform knowledge into internally usable representations, and organically combine new knowledge with original knowledge. Therefore, students are required to have a certain degree of reasoning ability, but the environment still has to do a lot of work. Teachers present and organize knowledge in some form so that the knowledge that students have can be continually increased. This learning method is similar to the school teaching method in human society. The task of learning is to establish a system that can accept teaching and advice, and effectively store and apply the learned knowledge. Many expert systems use this method to achieve knowledge acquisition when building a knowledge base. A typical application example of teaching learning is the FOO program.
3) Learning by deduction
The form of reasoning used by students is deductive reasoning. Reasoning starts from axioms and derives conclusions through logical transformation. This kind of reasoning is a process of "fidelity" transformation and specialization, which enables students to acquire useful knowledge in the process of reasoning. This learning method includes macro-operation learning, knowledge editing, and Chunking techniques. The inverse of deductive reasoning is inductive reasoning.
4) Learning by analogy
By using the similarity of knowledge in two different domains (source domain, target domain), the corresponding knowledge of the target domain can be derived from the knowledge of the source domain (including similar features and other properties) by analogy, thereby achieving learning. The analog learning system can transform an existing computer application system into a new field to perform similar functions that were not originally designed.
Analog learning requires more reasoning than the three learning methods described above. It generally requires that the available knowledge be retrieved from the knowledge source (source domain) and then converted into a new form for use in the new state (target domain). Analogy learning plays an important role in the history of human science and technology development. Many scientific discoveries are obtained through analogy. For example, the famous Rutherford analogy reveals the mystery of atomic structure by analogizing the atomic structure (target domain) with the solar system (source domain).
5) Exploration-based learning (EBL)
Based on the goal concept provided by the teacher, an example of the concept, domain theory and operational criteria, the student first constructs an explanation to explain why the example satisfies the target concept, and then generalizes the interpretation as a goal concept that satisfies the operational criteria. condition. EBL has been widely used in knowledge base refinement and improved system performance.
The famous EBL system includes G.DeJong's GENESIS, T.Mitchell's LEXII and LEAP, and S.Minton's PRODIGY. .
6) Learning from induction
Inductive learning is a collection of examples or counterexamples of a concept by a teacher or environment that allows students to derive a general description of the concept through inductive reasoning. This kind of learning has far more inferential work than teaching learning and deductive learning, because the environment does not provide general conceptual descriptions (such as axioms). To some extent, the amount of reasoning for inductive learning is greater than that of analog learning, because no similar concept can be used as a "source concept." Inductive learning is the most basic, and the more mature learning methods have been widely studied and applied in the field of artificial intelligence.
Classification based on representation of acquired knowledge
The knowledge acquired by the learning system may include: behavioral rules, descriptions of physical objects, problem solving strategies, various classifications, and other types of knowledge for task implementation.
For the knowledge gained in learning, there are mainly the following representations:
1) Algebraic expression parameters
The goal of learning is to adjust the algebraic expression parameters or coefficients of a fixed function form to achieve an ideal performance.
2) Decision tree
The decision tree is used to divide the generics of the objects. Each internal node in the tree corresponds to an object attribute, and each side corresponds to an optional value of these attributes. The leaf nodes of the tree correspond to each basic classification of the object.
3) Formal grammar
In the learning of a particular language, a formal grammar of the language is formed by summarizing a series of expressions of the language.
4) Production rules
Production rules are expressed as condition-action pairs and have been used very widely. The learning behaviors in the learning system are mainly: generation, generalization, specialization or synthetic production rules.
5) formal logic expression
The basic components of formal logic expressions are propositions, predicates, variables, statements that constrain the scope of variables, and embedded logical expressions.
6) Diagram and network
Some systems use graph matching and graph conversion schemes to effectively compare and index knowledge.
7) Framework and schema (schema)
Each frame contains a set of slots that describe various aspects of things (concepts and individuals).
8) Computer programs and other process codes
Obtaining this form of knowledge aims to achieve an ability to implement a particular process, rather than to infer the internal structure of the process.
9) Neural network
This is mainly used in connection learning. Learning the acquired knowledge is finally summarized into a neural network.
10) Combination of multiple representations
According to the degree of subtlety of the representation, the knowledge representation can be divided into two categories: a coarse-grained symbol with a high degree of generalization, and a sub-symbolic representation with a low degree of generalization. Like decision trees, formal grammars, production rules, formal logic expressions, frames and patterns, etc. belong to the symbolic representation class; algebraic expression parameters, graphs and networks, neural networks, etc. belong to the subsymbol representation class.
Classified by application area
The main application areas are: expert systems, cognitive simulation, planning and problem solving, data mining, network information services, image recognition, fault diagnosis, natural language understanding, robotics and games.
From the types of tasks reflected in the execution part of machine learning, most of the applied research areas are basically focused on the following two categories: classification and problem solving.
(1) The classification task requires the system to analyze the input unknown mode (the description of the mode) based on the known classification knowledge to determine the genericity of the input mode. The corresponding learning goal is to learn the criteria for classification (such as classification rules).
(2) Problem Solving Tasks require a sequence of actions to convert the current state to the target state for a given target state; most of the machine learning work in this field Focus on learning to gain knowledge (such as search control knowledge, heuristic knowledge, etc.) that can improve the efficiency of problem solving.
Comprehensive classification
1) Empirical inductive learning
Empirical induction learning uses some data-intensive empirical methods (such as version space method, ID3 method, law discovery method) to summarize the examples. The examples and learning results are generally represented by symbols such as attributes, predicates, and relationships. It is equivalent to inductive learning based on the classification of learning strategies, but deducts the part of joint learning, genetic algorithms, and reinforcement of learning.
2) Analytic learning
The analytical learning method is based on one or a few examples and uses domain knowledge for analysis. Its main features are:
· The reasoning strategy is mainly deductive, not inductive;
· Use past problem solving experience (instance) to guide new problem solving, or to generate search control rules that can more effectively apply domain knowledge.
The goal of analytical learning is to improve system performance, not new concept descriptions. Analytical learning includes techniques such as applied interpretation learning, deductive learning, multi-level structural chunking, and macro-operation learning.
3) Analogy learning
It is equivalent to analogy learning based on the classification of learning strategies. The more compelling research in this type of learning is to learn by analogy with specific examples of past experiences, called case-based learning, or simply paradigm learning.
Machine learning code example
Machine learning speech design to the latest languages such as pytho and R.
//Compile under gcc-4.7.2.
//Command line: g++-Wall-ansi-O2test.cpp-otest
#include<iostream>
usingnamespacestd;
voidinput(int&oper,constboolmeth)
{
//meth is true to judge only 1 and false to judge 1 or 0.
while(true)
{
cin>>oper;
if(meth&&oper==1)
break;
elseif(oper==0||oper==1)
break;
Cout<<" input error, please re-enter."<<endl;//Judge parameters
Cin.sync();//avoid extreme input leading to an infinite loop
cin.clear();
}
}
intmain(void)
{
Cout<<"1+1=2? It depends on how you taught me, don't be surprised if I will learn "<<endl;
Intladd, radd, aprs, rcnt(0), wcnt(0); // define input and result, correct number of times and number of errors
Cout<<" starts learning..."<<endl;
for(inti(0);i!=10;++i)
{
Cout<<" parameter 1 (must be 1): "<<flush;// prompt input parameters
input(ladd,true);
Cout<<" parameter 2 (must be 1): "<<flush;
input(radd,true);
Cout<<" Result: "<<(ladd+radd)<<endl;//Output result
Cout<<" Are you satisfied with this (satisfactory input 1, unsatisfactory input 0): "<<flush;//evaluation level
input(aprs,false);
If(aprs)//Judge user evaluation
++rcnt;
else
++wcnt;
Cout<<"correct number of times: "<<rcnt<<" error count: "<<wcnt<<endl;//errors
}
If(rcnt>wcnt)//Judge the learning result
Cout<<" The master told me 1+1=2."<<endl;
else
if(rcnt<wcnt)
Cout<<" The master told me 1+1!=2."<<endl;
else
Cout<<" I don't understand what the owner means."<<endl;
Intterm; / / exit part
Cout<<" Are you satisfied with my performance? Satisfied, please enter 1 dissatisfied, please enter 0:"<<flush;
input(term,false);
if(term)
Cout<<" Thanks, I will continue to study hard"<<endl;
else
Cout<<" Thank you, I will continue to work hard to learn D"<<endl;
//cin>>term;//enabled when testing on Windows
return0;
}
Intelligent Recommendation
Introduction to machine learning algorithms (sklearn)
Watched recently"Python Machine Learning and Practice"This book has gained a lot. So I am going to make a simple combing and summary of the main points in the book in the form of a table for...
Machine Learning Notes: Common Algorithms
Machine learning algorithm Visual learning of machine learning algorithms...

Summary of common algorithms for machine learning
Article directory Linear model Linear regression 2. Logistic regression 3. Regularization 4. FM,FFM,DeepFM LR&PLOY2 FM FFM Decision tree 1. Several commonly used tree models 2. Pruning strategy 3....

Common machine learning algorithms and their framework
The development of machine learning to today can be roughly divided into the followingTwo major categories: Traditional machine learning algorithms and deep learning algorithms Traditional machine lea...
Common machine learning algorithms illustration
Transfer: naughty https://my.oschina.net/taogang/blog/1544709 Edit: Python those things Whenever mentioned machine learning, we always get confused among the various algorithms and methods, I fe...
More Recommendation

Machine Learning Beginners-Common Algorithms
1. Types of ML algorithms 1. Supervised Learning: Supervised learning can be understood as: using labeled training data to learn the mapping function from the input variable (X) to the output variable...

Common types and algorithms of machine learning
1. Machine learning is a means to realize artificial intelligence. Its main research content is how to use data or experience to learn and build models, and make scientific predictions and evaluations...

9 common algorithms for machine learning
1. Common algorithm classification Classification KNN Logistic regression (logiscic) Decision tree Naive Bayes Support Vector Machine SVC Regression method KNN Ordinary linear regression (linear) Ridg...
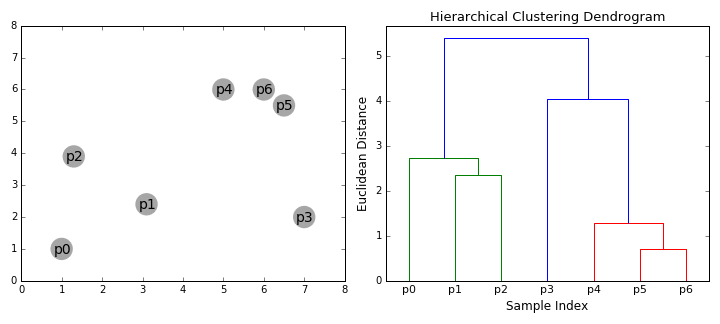
Machine learning-common clustering algorithms
1. Unsupervised learning What can we do with data without a label? Clustering Dimensionality reduction Outlier detection This blog introduces clustering in unsupervised learning. 2. About clustering O...
Outline of common machine learning algorithms
Final study report 0. Table of Contents Final study report 0. Table of Contents 1. Basic concepts 2. Multimedia Information Representation 2.1 Image 2.2 Video 2.3 Image feature extraction algorithm in...