Analysis of libpcap packet capture mechanism (3)
tags: system
At present, the network packet capture system under the Linux operating system is generally built on the libpcap packet capture platform. The English meaning of libpcap is Library of Packet Capture, that is, the packet capture function library. The C function interface provided by the library can be used in application systems that need to capture data packets that pass through the network interface (as long as the target address is not necessarily the local machine). In a high-traffic network environment, the inefficient packet capture technology based on libpcap cannot capture a sufficient number of network packets for use by upper-layer application systems.
1. Linux kernel protocol stack analysis and performance evaluation
In the libpcap system, the operating system kernel protocol stack provides users with a socket SOCK_PACKET working at the data link layer.libpcap enters the system kernel state from the user state through the socket application program interface, bypassing the TCP layer and IP layer processing in the kernel protocol stack and directly capturing the original network data frame from the data link layer. In order to deeply analyze the packet capture mechanism of libpcap, first, based on the linux-2.4.10 operating system, the message transmission mechanism and performance bottleneck of the traditional TCP/IP kernel protocol stack are studied.
1. TCP/IP protocol stack message transmission model
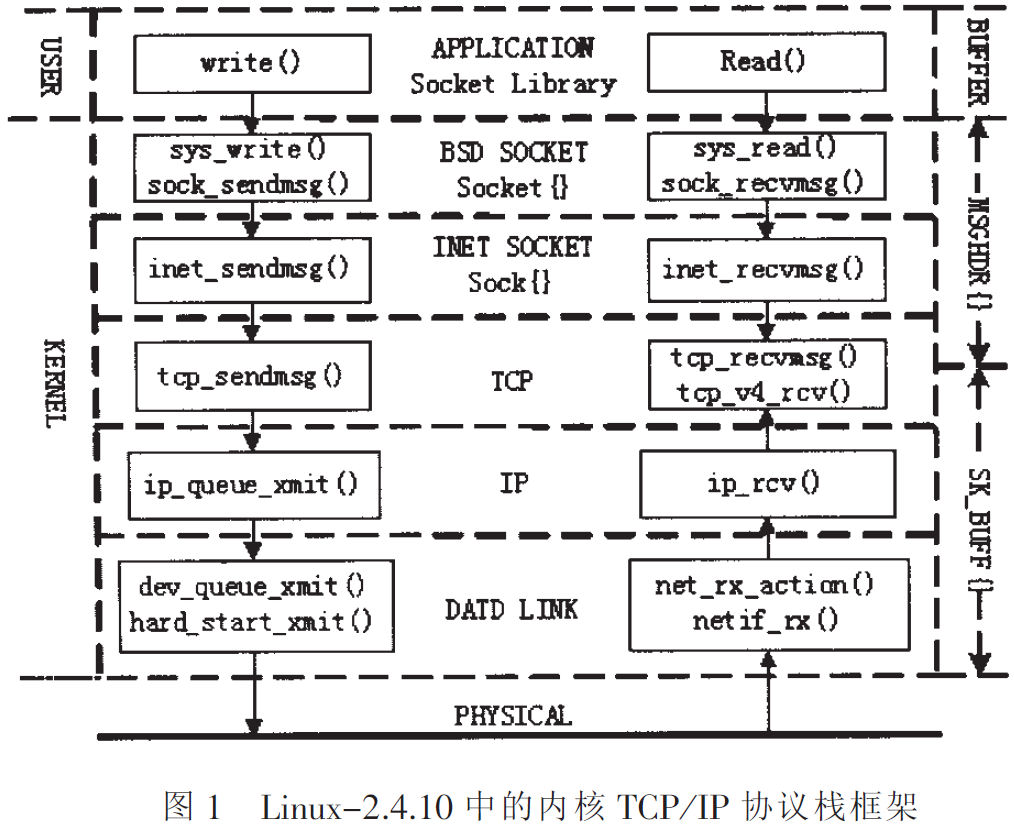
The kernel protocol stack of the Linux operating system can be basically divided into several parts such as the data link layer, IP layer, TCP/UDP layer, INET Socket layer, BSD Socket layer and application layer. Taking the transport layer protocol as the TCP protocol as an example, a typical TCP/IP protocol stack hierarchy and module structure are given in FIG. 1.
The kernel protocol stack includes a set of functions and several key data structures. The function call relationship of each protocol layer is shown in Figure 1. The socket socket library at the user level is maintained by the kernel's data structures struct socket and struct sock. The data is managed by two data structures struct msghdr and struct sk_buff in the process of sending/receiving. The struct msghdr is maintained by the BSD Socket layer and the INET Socket layer. The struct msghdr is used to store the address and size of the data buffer of the application layer. Each layer below TCP/IP uses struct sk_buff as a data buffer.The kernel implements the conversion of these two data structures through the memory copy operation in the tcp_sendmsg()/tcp_recvmsg() function. The kernel data buffer struct sk_buff does not perform data copy operations when passing through the layers below the TCP/UDP layer, but only moves the data pointer between different message protocol headers. This can avoid unnecessary system overhead。
2. Performance analysis of TCP/IP protocol stack message receiving process
Taking Intel 100M network card eepro100 as the physical layer device, comparing the kernel protocol stack framework in Figure 1, a detailed analysis of the message receiving process of the Linux system kernel protocol stack:
The message reception of the Linux kernel protocol stack is divided into two processes: a top-down process and a bottom-up process. The top-down process is a passive process. The system calls read() or recv()/recvfrom() to transfer the "required data" request through the upper protocol stack, and enters the TCP protocol layer through the tcp_recvmsg() function. The function tcp_recvmsg() will read data in the receive queue struct sk->receive_queue. If the required data is not in the receive queue, the current process where the function tcp_recvmsg() is located will sleep and wait on the struct sk->receive_queue receive queue . When the system wakes up the suspended process again, the tcp_recvmsg() function will read the required data and call the tcp_v4_do_rcv() function to fill the data in the struct sk->backlog queue into the sk->receive_queue queue while awakening and waiting in this Processes on the queue. The tcp_recvmsg() function copies the data packet from the kernel buffer to the application buffer during the reading of the data packet. The bottom-up process is as follows:
- When the network data packet arrives, the eepro100 network card transmits the data packet to the network card driver buffer ring through DMA and generates a hardware reception interrupt at the end of the data transmission. The system calls the corresponding hard interrupt handler according to the interrupt type, and thus the kernel protocol stack completes the conversion from the physical layer to the data link layer.
- In the hard interrupt handler speed_rx(), the kernel processes the received data packets and adds the data in the driver buffer ring to the system receive queue by calling the netif_rx() function. The operating system calls the upper soft interrupt processing function net_rx_action() at idle time. In the function net_rx_action(), the corresponding processing function ip_rcv() is called according to the registered packet type (such as ETH_P_IP). In this way, the core protocol stack enters the IP layer from the data link layer.
- In the ip_rcv function, call tcp_v4_rcv() when judging that the data should be sent to the upper layer TCP protocol for processing according to the routing result. This function will call tcp_v4_do_rcv(), and fill the data in the struct sk->backlog queue into the struct sk->receive_queue queue through the function tcp_v4_do_rcv().
In order to test the system overhead of the kernel protocol stack during the message reception process (consuming CPU time), the driver of the network card was modified under Linux and some code was inserted in the system kernel to record the time when the message arrived at each part Poke, so you can determine the time cost of each part. The test results are shown in Table 1.

As can be seen from the table, the processing time of system hard interrupts (from speedo_rx() to net_rx_action()) accounts for about 20%, and the system overhead of soft interrupt processing (net_rx_action() Tcp_recvmsg()) accounts for about 15%, and from tcp_recvmsg() to inet_recvmsg(), about 55% of CPU time is consumed due to the data memory copy operation. System calls take up about 5% to 6% of CPU time. The cost of memory copy operations is expensive, mainly for the following reasons:
- The memory bus bandwidth is limited, and each memory copy takes up bandwidth;
- Each copy operation consumes a lot of CPU cycles. Usually, the CPU moves data from the source buffer to the destination buffer verbatim. This means that the CPU is not available during the copy operation;
- The data copy operation affects the system cache performance. Because the CPU accesses the main memory through the cache, the useful information that resides in the cache before the copy operation is cleared and then replaced by the copied data.
2. Analysis of traditional packet capture mechanism based on libpcap
libpcap uses the socket SOCK_PACKET working at the data link layer to complete the reading of network data packets. Taking Intel 100M network card eepro100 as an example, the process of analyzing the packet capture of libpcap is as follows:
- When the network data packet arrives, the eepro100 network card transmits the data packet to the network card driver buffer ring through DMA and generates a hardware reception interrupt at the end of the data transmission. The system calls the corresponding hard interrupt handler according to the interrupt type.
- In the hard interrupt handler speedo_rx(), the kernel processes the received data packets and adds the data in the driver buffer ring to the system receive queue by calling the netif_rx() function. The operating system calls the soft interrupt processing function net_rx_action() in the second half of the interrupt processing at idle time. The main function of this function is to check the type of data packet registered in the system and call the corresponding processing function. The registration packet type corresponding to libpcap is ETH_P_ALL, and its processing function is packet_rcv(). packet_rcv() still works at the data link layer.
- In the packet_rcv function, directly call skb_queue_tail() to store the data packet in the struct sk->receive_queue queue. In this way, the data packet bypasses the processing of the TCP layer and the IP layer in the receiving process.
- The packet_recvmsg() function sleeping on the queue struct sk->receive_queue receives the link layer data frame and copies the data frame to the application layer buffer.
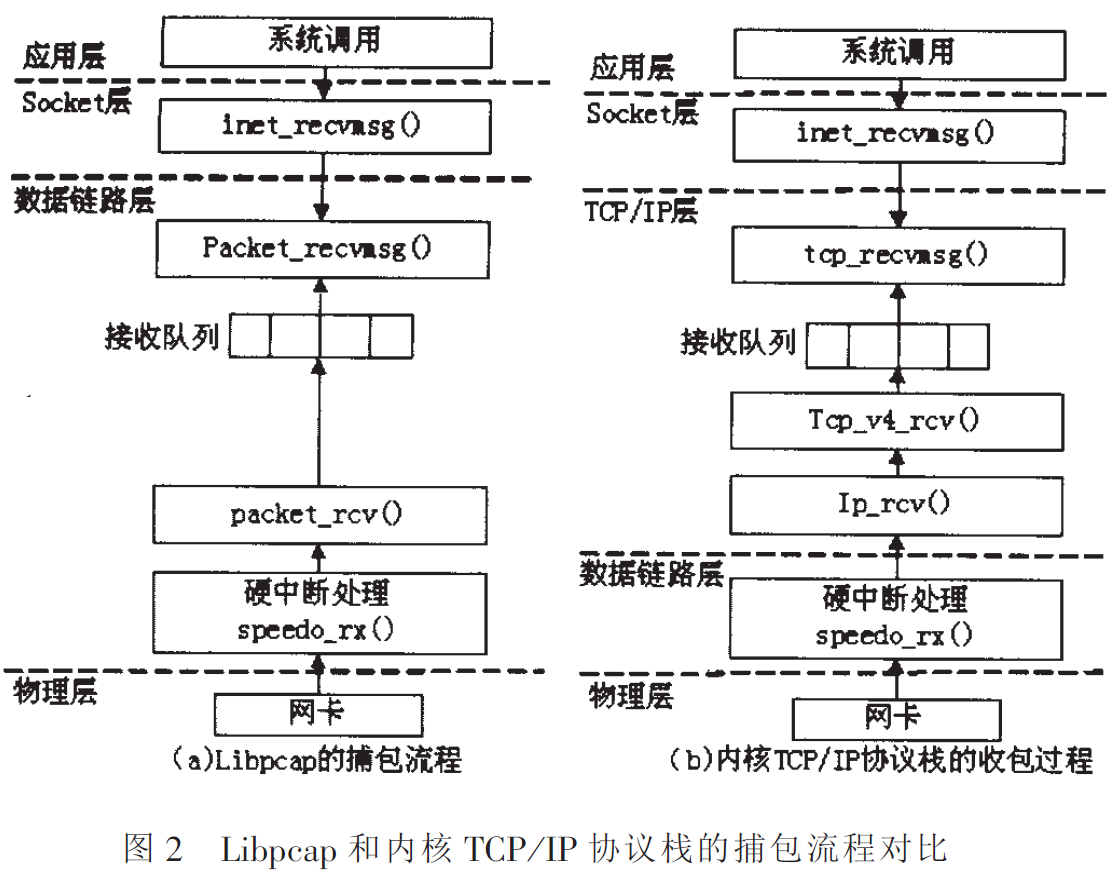
The comparison between the packet capture process of libpcap and the message receiving process of the kernel TCP/IP protocol stack is shown in Figure 2. It can be seen from the figure that compared with the packet receiving process of the traditional kernel TCP/IP protocol stack, libpcap bypasses the processing of the TCP layer (UDP layer) and the IP layer, and directly copies the data packet from the data link layer to In the application buffer. This can save the CPU time consumed by the data packet during the reception process. As can be seen from Table 1, about 10% of the processing time is saved. However, in the process of libpcap packet capture, system calls, data copying and kernel interrupt handling are still the main performance bottlenecks of the system.
3. Optimization measures for libpcap packet capture
Aiming at several time-consuming links in the libpcap packet capture process, optimization and improvement were made in order to reduce system resource consumption, and at the same time improve the libpcap packet capture performance under high-flow network environment. Several main measures for packet capture optimization are proposed below and their advantages and disadvantages are analyzed.
1. Add kernel filtering mechanism
Kernel filtering is to determine whether the received data packet is a message of interest to the application in the part equivalent to the soft interrupt handler (packet_rcv() function). If it is, copy it to the application layer buffer, otherwise discard it. This can greatly reduce the number of packets actually processed by the system, thereby improving the efficiency of packet capture. However, this method only works for certain applications, and it does not play a big role in some applications such as traffic statistics and common protocol analysis, because these applications often have to process most of the packets on the network.
2. Move the main application processing to the kernel module processing program
Because the system call involves 0x80 interruption on-site saving and process switching, frequent system calls in a large-flow network environment are very time-consuming work. Therefore, many applications treat the main application layer processing part as an LKM module in the kernel, which can reduce the number of system calls. However, to do so, the application process needs to be written in the driver module or the kernel code. There are many differences between the method of writing code in the kernel and the application layer and the functions used, and the method of memory allocation and reading and writing of user data has also changed. The complexity and difficulty of kernel coding have increased. In addition, the kernel code has high requirements for stability. Once the kernel program fails, it will cause the entire system to crash. Therefore, this method is generally suitable for applications that require high processing efficiency and relatively simple processing, such as firewalls.
3. Copy multiple messages to the user buffer at one time
libpcap reads the data packet through the system call revfrom(), and each time the function is called, it only passes a data packet to the user area. Therefore, it is possible to save a certain number of packets in the kernel buffer, and wake up the user process to read all the data packets in the kernel buffer when the packets reach a certain number. This saves time for user process switching. It is a very effective method when processing large-flow data packets. However, this will delay the time for the message to reach the user process. When the packet arrival rate is large, the time delay will increase significantly.
4. Bypass the kernel protocol stack
The data memory copy operation from the kernel to the application layer is the main performance bottleneck of the packet capture system. To this end, zero-copy technology can be used to convert the virtual address of the user buffer into a physical address available for the network card and lock the address by adding a processing module in the kernel. Improve the network card driver to obtain the physical address of the user buffer and use the network card asynchronous DMA to transfer data packets from the network card directly to the user space, which can bypass the operating system kernel protocol stack and reduce system kernel processing, data copying and system calls s expenses. This method can greatly improve the system's packet capture performance and even reach the performance limit of the network card. However, due to the need to modify the network card driver, it limits the versatility of this method.
5. Reduce the frequency of system hardware interrupts
When the rate of network packets reaching the system is too frequent, there will be situations where the CPU processing time is all used for interrupt processing. At this time, the system frequently runs the hard interrupt processing program, resulting in the upper soft interrupt processing not running. The hard interrupt handler fills the network buffer into the system buffer, so that the system buffer is quickly filled, and excess data packets will be discarded. At the same time, other processes cannot obtain control of the CPU. Therefore, reducing the interruption frequency is necessary to improve the performance of large-flow network packet capture systems. In some improved methods, when it is found that the interrupt frequency is too high, the hardware interrupt is forbidden, so that although some packets will be lost, the system will have the opportunity to respond to other processes. Some systems use a mixed interrupt and polling mechanism to reduce the frequency of system interrupts. The polling watchdog mechanism proposed by Macquelin et al. is one such method.
Intelligent Recommendation
IP packet capture library use Libpcap LAN
Experimental requirements Source and destination physical address of the print data packet; Print source IP and destination IP address; Printing upper layer protocol type; If the upper layer protocol ...
libpcap network packet capture function library
download Compile and install Instance The C function interface provided by the library is used to capture data packets passing through the specified network interface. download: http://www.linuxfromsc...

Design and implementation of network packet capture and traffic online analysis system-based on libpcap on MacOS Record this happy (DT) week
Design and implementation of network packet capture and traffic online analysis system-based on libpcap on MacOS Record this happy (DT) week Claim: Design and implement a network flow analysis system ...
libpcap/tcpdump—3—Packet capture conclusion (3 packets captured, 3 packets received by filter, 0 packets dropped by kernel)
Every time when you exit tcpdump, the terminal will display the above three lines of information. This article is to explain the relevant information of these 3 values. I will try my best to write in ...

TLS1.3 packet capture analysis (3) - EncryptedExtentions, etc.
In fact, when I first captured the packet, I found a problem. After the ChangeCipherSpec message, there are no encrypted extensions, certificates, or even Finished messages. During the handshake proce...
More Recommendation
3.ICMP_ packet capture analysis traceroute traceroute
First, the traceroute program traceroute / tracert Traceroute Linux and Mac OS systems default route provides tracking applet, Tracert is a Windows system default route provides tracking applet. Both ...
Analysis of Ali's App Packet Capture (3)
The last article "Analysis of Ali Packet Capture (2)" briefly introduced the initialization of Mtop and foundIMtopInitTaskIt is mainly used to handle the initialization of Mtop. After viewin...

Wireshark packet capture analysis (3) TCP protocol
Bit means 1bit, excluding optional fields (options and data), a total of 160bit, which is 20 bytes The source port number and destination port number are used to find the sender and receiver [source p...
Cisco Packet Capture and Analysis of Layer 3 Routing
Three-layer routing packet capture analysis This experiment uses the packet capture tool that comes with Cisco Packet Tracer. Related commands: arp -a to view the arp table, arp -d to release the arp ...

Network packet capture function library Libpcap installation and use (very powerful)
1. Introduction to Libpcap Libpcap is the abbreviation of Packet Capture Libray, which is the data packet capture function library. The C function interface provided by the library is used to capture...