MediaPipe integration facial recognition, human body attitude evaluation, human hand detection model
tags: Depth study Face recognition
Last articleWe introduced the basics of MediaPipe Holistic, learned that MediaPipe Holistic is separately used.MediaPipe Pose,MediaPipe Face MeshwithMediaPipe HandsThe gestures, facial and hand-bound models generate a total of 543 migrators (33 posture bounding standards per hand, 468 face bounds and 21 handbases).
The accuracy of the gesture model is sufficiently low so that the ROI of the result is still insufficient enough, but we run additional light hand to rearily cut the model, the model played, and only 10% of the hand model about.

MediaPipe
MediaPipe is an application framework for multimedia machine learning model developed by Google Research and open source. In Google, a series of important products, such as Google Lens, Arcore, Google Home, and, have depressed MediaPipe.

MediaPipe picture detection
As a cross-platform frame, MediaPipe can not only be deployed on the server, but also in multiple mobile (Android and Apple iOS) and embedded platforms (Google Coral and Raspberry) as a device-end machine learning reasoning (ON) -Device machine learning inference frame.
The success or failure of a multimedia machine learning application is dependent on the model itself, but also depends on the effective delivery of equipment resources, high-efficiency synchronization between multiple input streams, across platform deployment, and fast and no.
Based on these needs, Google has developed and opened the MediaPipe project. In addition to the above features, MediaPipe also supports TensorFlow and TF Lite's reasoning engine (Inference Engine), any Tensorflow and TF Lite models can be used on MediaPipe. At the same time, the MEDIAPIPE also supports the GPU acceleration of the device itself in the mobile terminal and the embedded platform.
MediaPipe main concept
MediaPipe's core framework is implemented by C ++, and provides support for languages such as Java and Objective C. The main concept of MediaPipe includes packets, streams, calculation units, graphs, and subgraphs. The packet is the most basic data unit, and a packet represents data on a particular time node, such as a frame image or a small audio signal; the data stream consists of a plurality of packets arranged in a time sequential ascending, one A particular timestamp of the data stream allows only one to more than one packet; and the data stream is flowing in the figure composed of a plurality of computing units. The MEDIAPIPE map is an outgoing-data package from the data source (Source Calculator or Graph Input Stream) flows into the diagram until the aggregate node (Sink Calculator or Graph Output Stream).
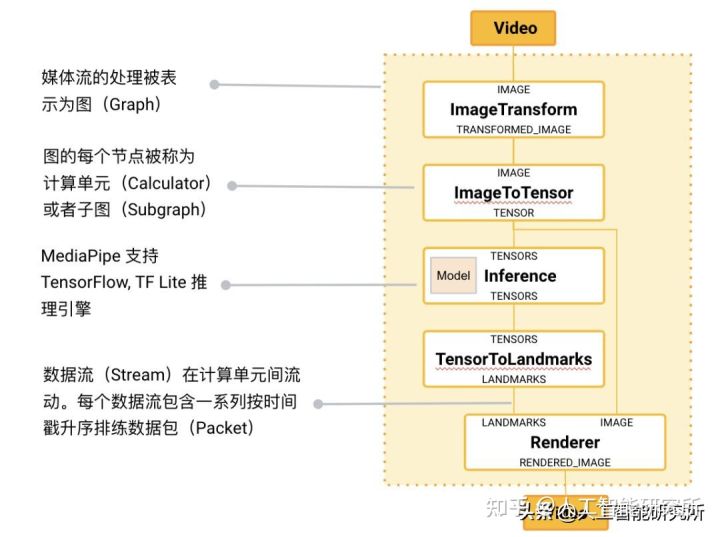
MediaPipe core framework
If we want to use MediaPipe,
First, enter in our computer cmd command box
Python -m Pip Install MediaPipe Installing a third party model,
Then we can use the code to perform pictures or video detection,
The main advantage of this model is that we don't need we download the pre-training model, just installing its MediaPipe package
MediaPipe picture detection
Image code detection of MediaPipe model
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_holistic = mp.solutions.holistic
file = '4.jpg'
holistic = mp_holistic.Holistic(static_image_mode=True)
image = cv2.imread(file)
image_hight, image_width, _ = image.shape
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = holistic.process(image)First, we import the required third-party libraries and configure the size of the points that need to draw the points, the line size and color, etc., this information can be modified, here we directly refer to the official configuration (MP.Solutions.drawing_utils function )
Then define a HOLISTIC detection model function
mp_holistic = mp.solutions.holistic
file = '4.jpg'
holistic = mp_holistic.Holistic(static_image_mode=True)Then use the relevant knowledge of the OpenCV introduced in our previous introduction to read the picture we need to detect from the system and get the size of the picture.
image = cv2.imread(file)
image_hight, image_width, _ = image.shapeSince the OpenCV default color space is BGR, but usually we say that the color space is RGB, where MediaPipe modifies color space
Then use the Holistic detection model established in front to detect the picture.
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = holistic.process(image)The results after the model detection are saved in Results, we need to access this result and draw the detected face, hand, and gesture data points on the original detection picture to view
if results.pose_landmarks:
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].y * image_hight})'
)
annotated_image = image.copy()
mp_drawing.draw_landmarks(
annotated_image, results.face_landmarks, mp_holistic.FACE_CONNECTIONS)
mp_drawing.draw_landmarks(
annotated_image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(
annotated_image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(
annotated_image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS)Here we print the results of the picture detection and draw some face detection model data, the detection data of the left and right hands, and human gesture detection data
#cv2.imshow('annotated_image',annotated_image)
cv2.imwrite('4.png', annotated_image)
cv2.waitKey(0)
holistic.close()After the drawing is completed, we can display the picture to make it easy to use the OpenCV's IMWRITE function to save the results picture. Finally, only the Close Holistic detection model is required. Here is a problem when detecting many people, just detecting a single, Our later studies

Picture detection
Video code detection of MediaPiPE model
Of course, we can also perform MediaPipe model detection directly in the video.

import cv2
import time
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_holistic = mp.solutions.holistic
holistic = mp_holistic.Holistic(
min_detection_confidence=0.5, min_tracking_confidence=0.5)First, consistent with the picture test, we build a Holistic test model, then open the camera to detect the model
cap = cv2.VideoCapture(0)
time.sleep(2)
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = holistic.process(image)First we open the default camera and get the real-time picture from the camera.
cap = cv2.VideoCapture(0)
while cap.isOpened():
success, image = cap.read()After detecting pictures, we can use the steps detected by the image to perform the detection of the model.
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = holistic.process(image)Here we use Cv2.flip (Image, 1) image flip function to enhance data image, because the images in our camera are mirroring relationships
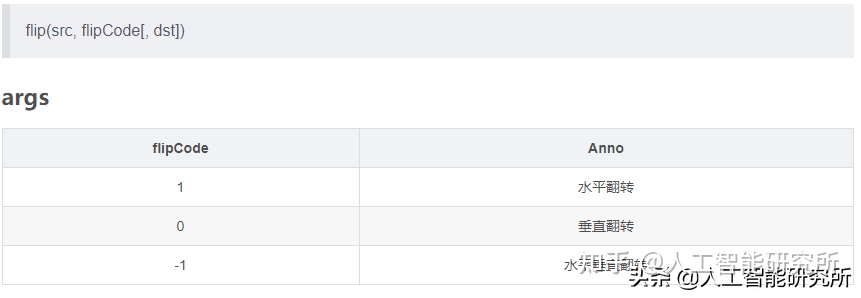
cv2.flip(image, 1)
With this function, you can mirror our image image, and finally assign the picture to the Holistic model.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image, results.face_landmarks, mp_holistic.FACE_CONNECTIONS)
mp_drawing.draw_landmarks(
image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(
image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(
image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS)
cv2.imshow('MediaPipe Holistic', image)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
holistic.close()
cap.release()After the test is complete, we can draw the data in real time to see the results in the video.

Video detection
Here, due to the default setting, the size of the line and the point is not appropriate, we will slowly optimize later.
WeChat search applet: AI artificial intelligence tool, experience different AI tools

Intelligent Recommendation

Paddledtection-implemented human body detection
Man traffic statistics Project overview In public places such as subway stations, railway stations, airports, exhibition halls, scenic spots, require real-time detection of people's flow, timely warni...
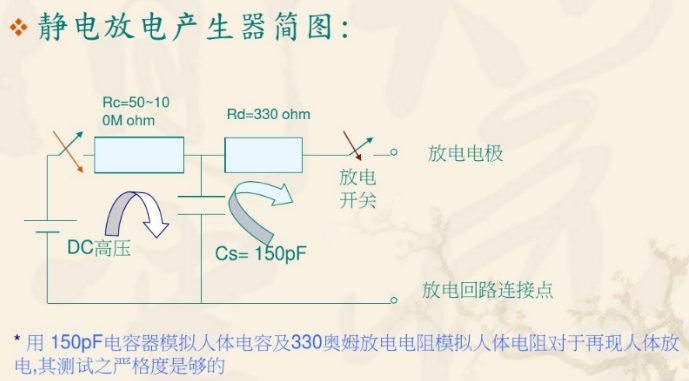
Human body electrostatic discharge model
Human body electrostatic discharge model The electrostatic discharge model is divided into: HBM: Human Body Model, human body model; HBM: Human Body Model, human body model :; CDM: Charged Device Mode...
【2】 MediaPipe facial recognition
Last time, I have not been updated after I wrote the gesture recognition of MediaPipe. Today I wrote a face test Web reference: https://google.github.io/mediapipe/solutions/face_detection.html MediaPi...
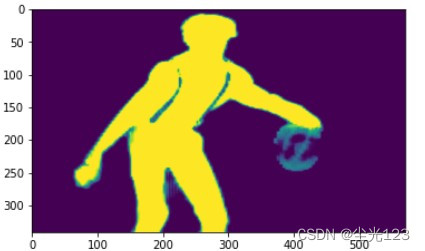
【MediaPipe】 Human eloquent cutting
Foreword Due to the division module of MediaPipe, the character division can be achieved, and the human body pictures can be matched Code Import library Define the picture function Read into the image...
More Recommendation
Machine vision Python+MediaPipe+OpenCV to realize human posture recognition (1)
Articles directory 1. What is MediaPipe? 2. Use steps 1. Introduction to the library 2. Main code 3. Run results 1. What is MediaPipe? Mediapipe official website 2. Use steps 1. Introduction to the li...

A very interesting flash human body hour hand
I recently saw a very interesting hour hand on my colleague’s personal blog, which is from a Japanese personal blog.http://chabudai.org/blog/?p=59 I want to see the effect. How to achieve it? In...
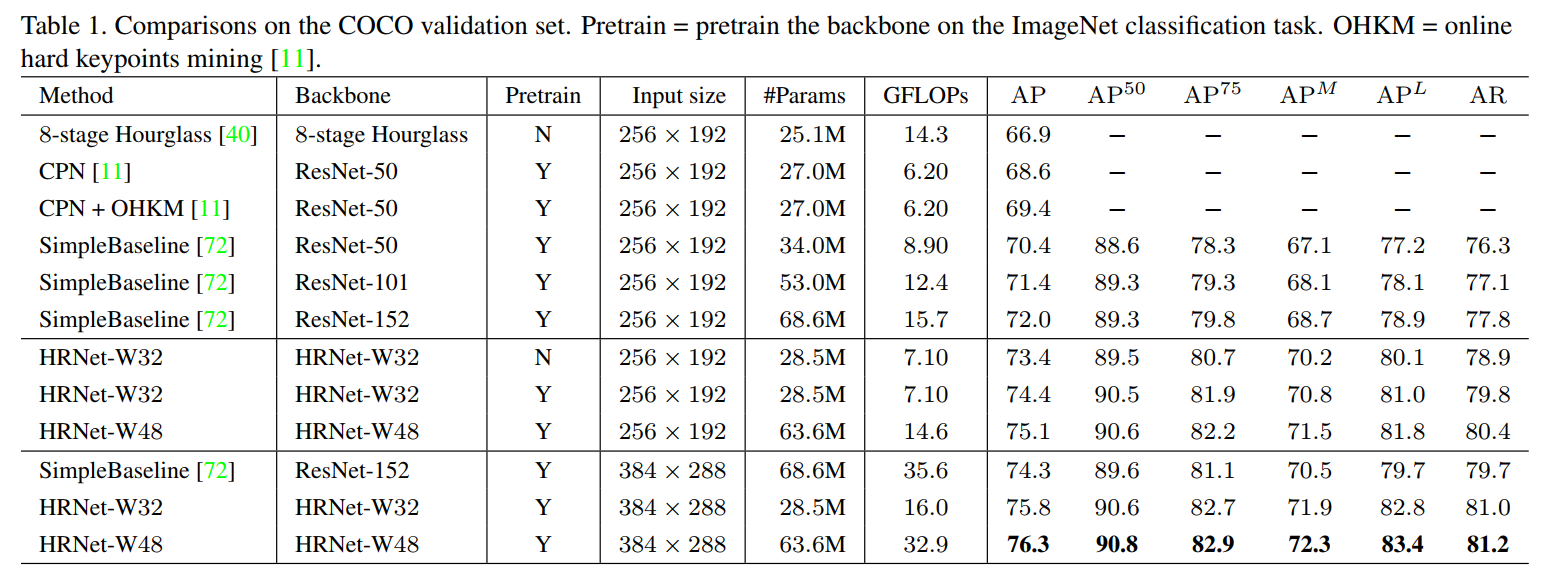
Attitude estimation 1-04: HR-Net (Human Body Estimation)
The following links are all personal opinions about HR-Net (Human Body Estimation). If you have any mistakes, you are welcome to point them out. Interested friends can add WeChat: a944284742 to discus...
Human body attitude estimation DEMO Interpretation Java and Python
The model is trained to the actual application, mainly with the collection of data sets, adjusts the parameters to train, deploy, and more. This article mainly introduces the steps in deploying the mo...
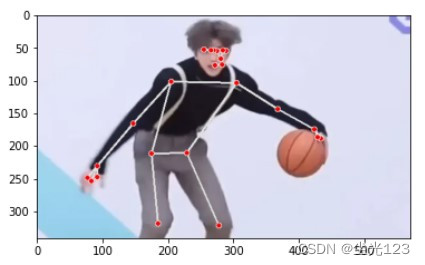
Key point detection based on human pictures based on MediaPipe
Foreword In the previous blog, the environmental configuration of MediaPipe has been given. This blog will share the key points detection of human pictures based on MediaPipe and the scene in 3D Key p...