L1 Regularization and L2 Regularization Interview Questions
tags: Machine learning knowledge
Regularization
L1 regularization and L2 regularization can be regarded as penalty terms of the loss function. The so-called "punishment" refers to some restrictions on some parameters in the loss function
L1 regularization refers to the sum of the absolute values of the elements in the weight vector w
L2 regularization refers to the sum of the squares of the elements in the weight vector w and then the square root
The difference between L1 regularization and L2 regularization
L1 regularization can produce a sparse weight matrix, ie a sparse model can be used for feature selection
L2 regularization can prevent the model from overfitting; to a certain extent, L1 can also prevent overfitting
Why can regularization reduce the degree of overfitting? And the following L1 regularization and L2 regularization will be explained.
Reduce the degree of overfitting: The reason why regularization can reduce overfitting is thatRegularization is a strategy to minimize structural risk. Adding a regularization term to the loss function can make the newly obtained optimization objective function h = f+normal, you need to make a trade-off between f and normal. If you still optimize f only as before, then It may be more complicated to get a set of solutions, so that the regular term is larger, then h is not optimal, so it can be seen that adding regular terms can make the solution simpler.By reducing model complexityTo get a smaller generalization error and reduce the degree of overfitting.
L1 regularization and L2 regularization: L1 regularization is to add the regularization term after the loss function to the L1 norm, plus the L1 norm is easy to getSparse solution(0 more). L2 regularization is to add the regularization term to the square of the L2 norm after the loss function, plus the L2 regularization compared to the L1 regularity, the resulting solution is comparedsmooth(Sparse from time to time). But it can also ensure that there are many dimensions close to 0 (but not equal to 0, so it is relatively smooth) in the solution, which reduces the complexity of the model.
Why can L1 regularity produce sparse models (many parameters = 0), while L2 regularity does not appear to have many parameters of 0?
Limit the solution of W to the black area, and at the same time make the empirical risk as small as possible, so the intersection point is the optimal solution, as can be seen from the figure, because L1 regular black area is Angular, so it is easier to get intersections at the corners, resulting in a situation where the parameter is 0
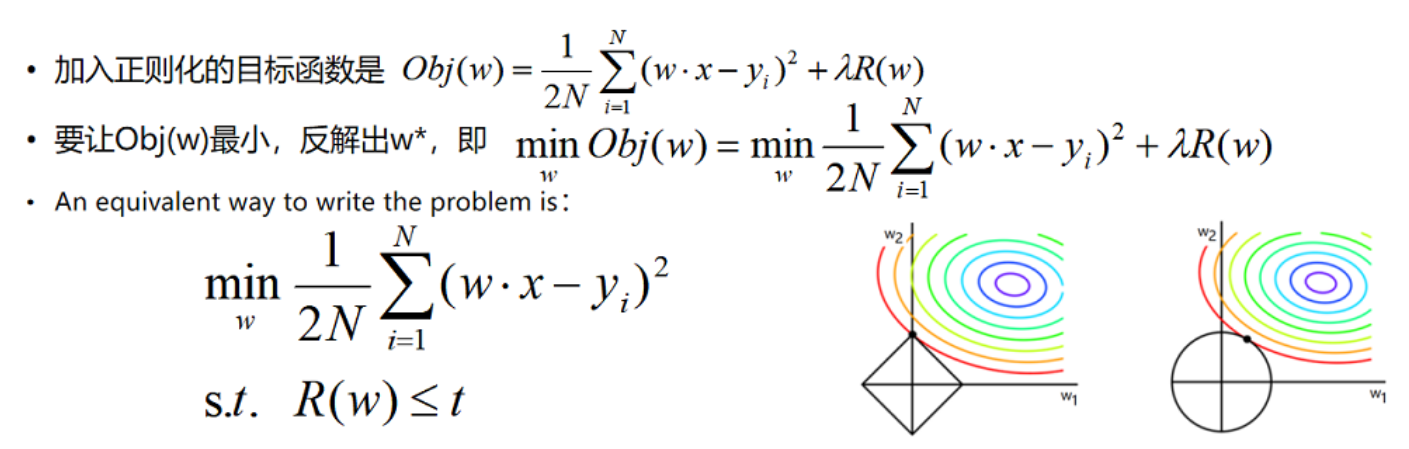
Reference article
Reference article 1
Reference article 2
Reference Article 3
Intelligent Recommendation
Machine learning, regularization (L1 regularization, L2 regularization)
Regularization Regularization 1. Regularization introduction 2. Common regularization methods 2.1 0 norm 2.2 L1 norm 2.3 L2 norm 2.4 Q-norm summary Regularization 1. Regularization introduction Regula...
L1, L2 regularization
What is regularization? Regularization is an "item" added to the model. Let's look at a diagram first. For such a model, it scores very well on the training dataset, but there is a problem, ...

L1 and L2 regularization intuitive
Regularization is used to solve the problem of model overfitting. It can be regarded as a penalty term for the loss function, that is, it imposes certain restrictions on the parameters of the model. A...
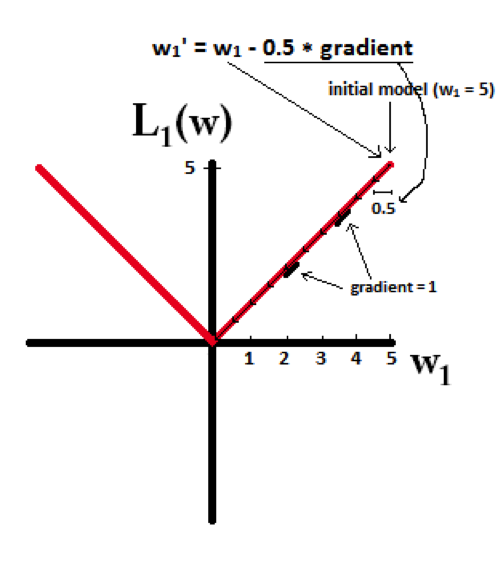
Explain L1, L2 regularization
When using machine learning to solve real problems, we usually use the L1 or L2 norm for regularization, which limits the weight and reduces the risk of overfitting. Especially when using gradient des...

L2/L1 regularization method
The L2/L1 regularization method is the most commonly used regularization method, which comes directly from traditional machine learning. The L2 regularization method is as follows: The L1 regul...
More Recommendation

L1 L2 regularization
In the machine learning algorithm, if we are looking for a model to fit the data as much as possible so that the training data is minimized, then the prediction accuracy is not high for the new data, ...

Understanding of L1 and L2 regularization
Excerpt from: Minimization of the structure of regularization understanding First give an example explanationThe role of L1 can make the model obtain a sparse solution Click to view: L1 regular can ma...

L1 and L2 regularization
It is highly recommended to watch this blog:Very good and comprehensive blog First, the principle of Occam’s razor: Among all the models that may be chosen, we should choose a model that is very...

Regularization (L1 and L2 norm)
To tell the truth, so to write after regularization is very strange. I believe we all know that the loss of function, is used to describe the gap between our model and the training data (ie whether it...

L0, L1, L2 regularization
In the concept of machine learning, we often hear L0, L1, L2 regularization, this paper summarizes several simple regular overtaken. 1, the concept of L0 regularization parameter value is the number o...