Data analysis-iris data set
Iris data set
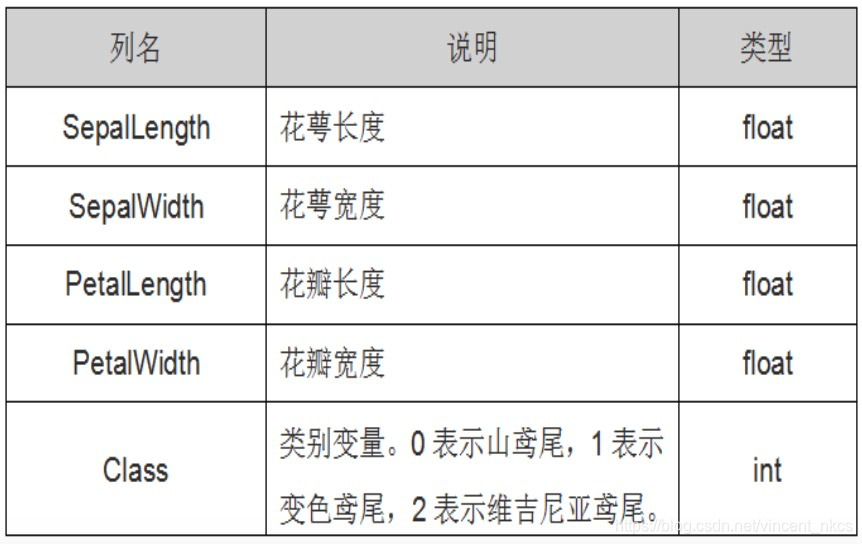
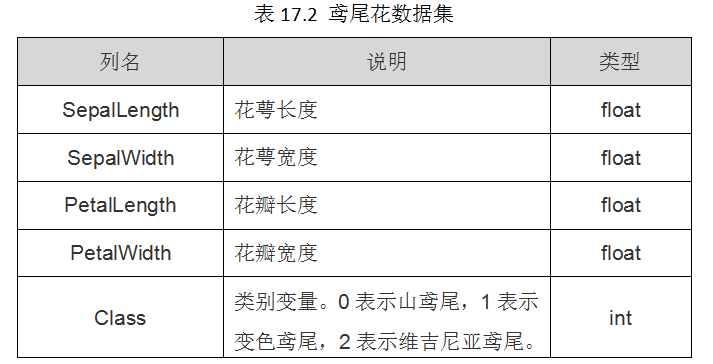
The Iris iris data set contains 3 categories, namely Iris-setosa, Iris-versicolor and Iris-virginica, with a total of 150 records, each with 50 data. Each record has 4 characteristics: calyx length, calyx width, petal length, petal width.
- sepallength: sepal length
- sepalwidth: sepal width
- petallength: petal length
- petalwidth: petal width
The units of the above four characteristics are all centimeters (cm)
1. How to import data sets with numbers and texts.
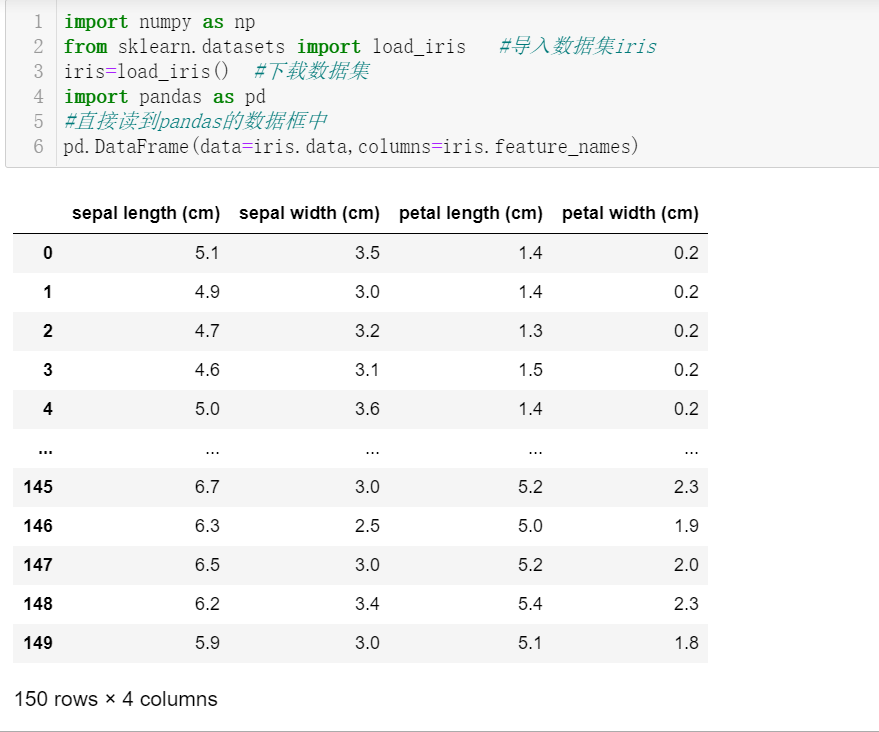
2. Find the average, median and standard deviation of the sepal length of Iris plants.
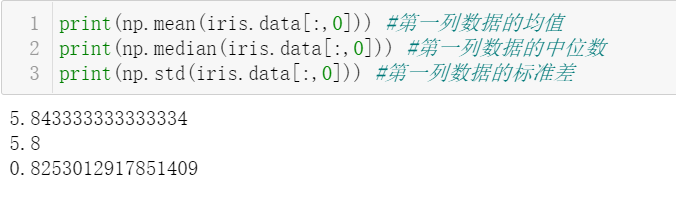
3. Create a standardized form of the sepal length of Iris plants whose value is exactly between 0 and 1, so that the minimum value is 0 and the maximum value is 1.
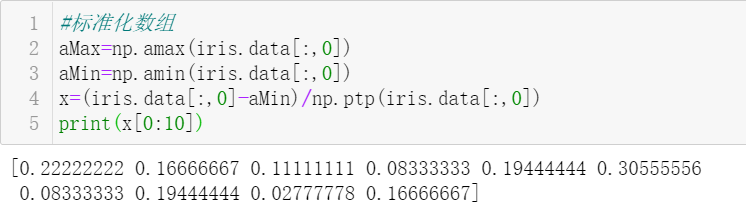
4. Find the 5th and 95th percentiles of the sepal length of Iris plants.
5. Modify 20 random positions in the iris_data data set to np.nan values.

6. Find the number and position of missing values in sepallength of iris_data.

7. Filter iris_data rows with sepallength (column 1) <5.0 and petallength (column 3)> 1.5.
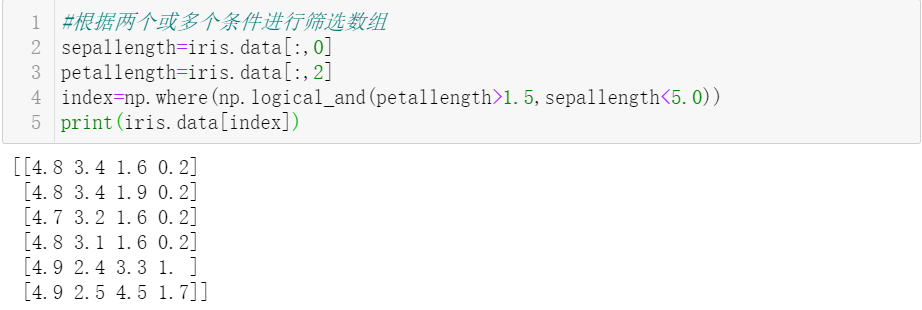
8. Select the iris_data row without any nan value.

9. Calculate the correlation coefficient between sepalLength (column 1) and petalLength (column 3) in iris_data.

10. Find out if there are any missing values in iris_data.

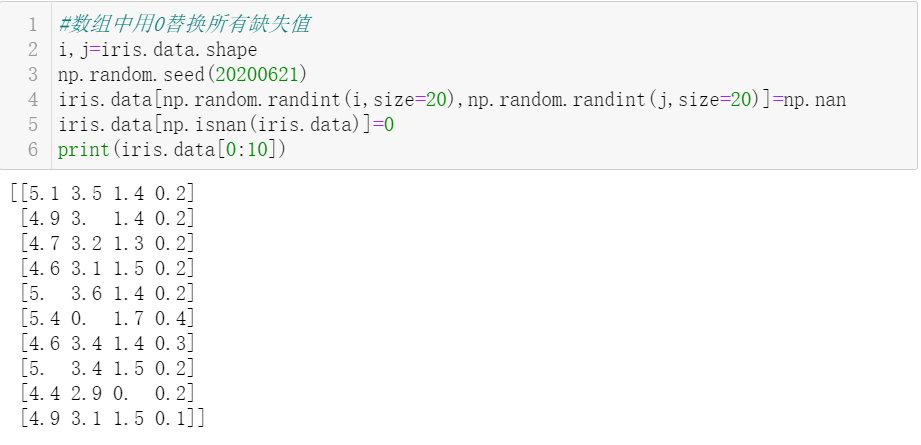
11. Replace all occurrences of nan with 0 in the numpy array.
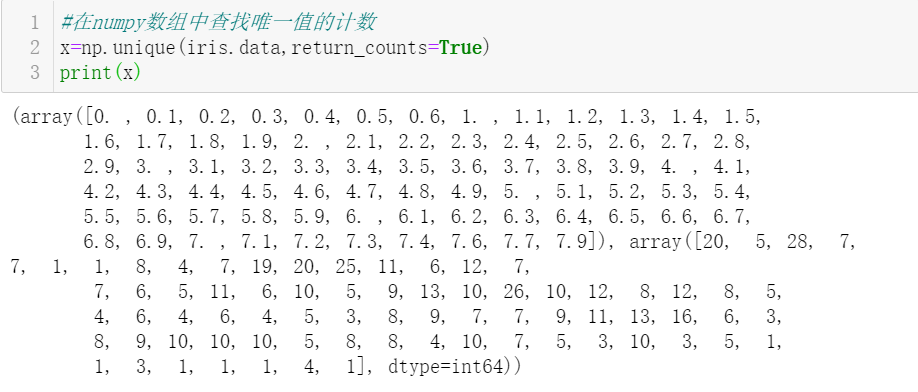
12. Find the unique value and the number of unique values in the iris species.
13. Display the petal length of iris_data (column 3) in the form of a categorical variable. Definition: Less than 3 -->‘small’; 3-5 --> ‘medium’;’>=5 --> ‘large’.

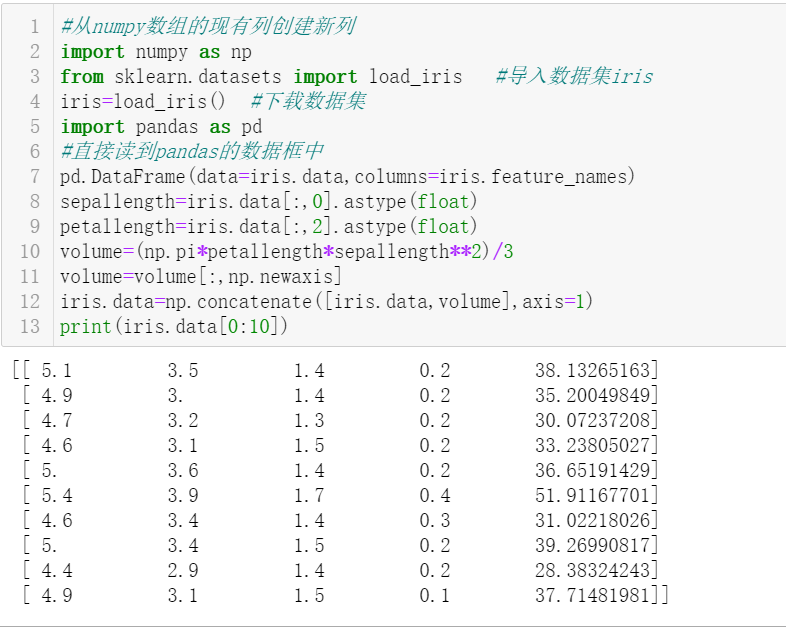
14. Create a new column in iris_data, where volume is(pi x petallength x sepallength ^ 2)/ 3 。
15. Randomly select the species of Iris plants so that the number of Iris-setosa is twice the number of Iris-versicolor and Iris-virginica.
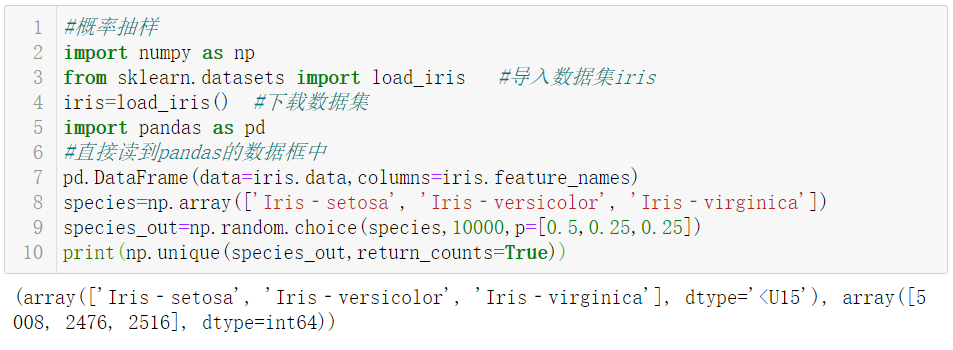
16. Sort the data set according to the sepallength column.

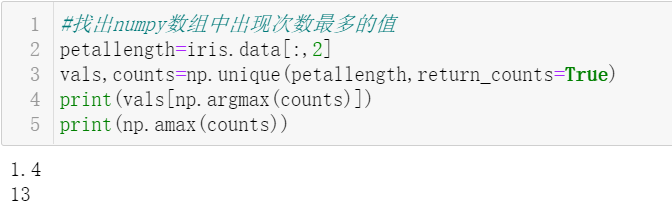
17. Find the most common petal length value in the iris data set.
18. Find the position where the value of the first occurrence is greater than 1.0 in the petalwidth (column 4) of the iris data set.

Intelligent Recommendation
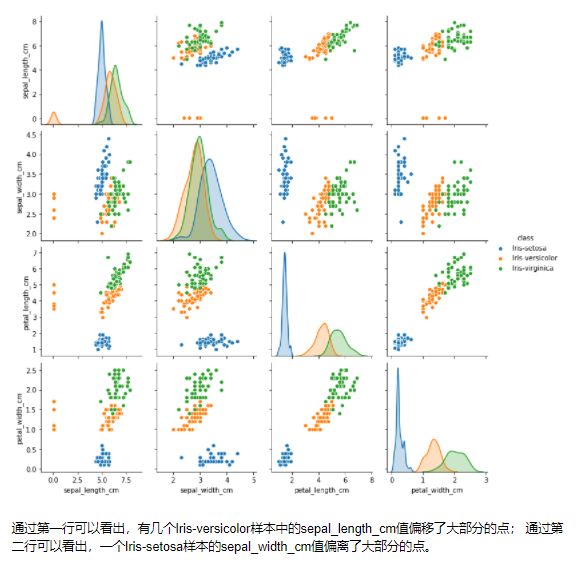
Python Data Analysis Project Example 2: Iris Data Set Analysis
IRIS Dataset Download (Free): Analysis software used:jupyter notebook Main grammar knowledge: Python data cleaning and finishing, Seaborn data visualization. Import data The iris data set is often use...
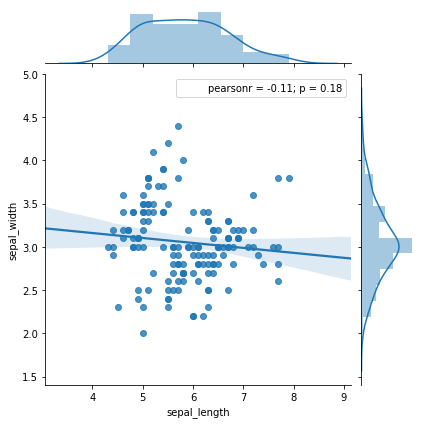
Iris Data set visulization
Because it is often necessary to visualize what the data is, but there is no time to sort out a complete system, so it is better to use the most classic data set to make a demo for reference. About Ir...
Iris flower data set
Download the module first: Call the package: Load the data set: Iris contains two properties: iris.data and iris.target Data is a matrix, each column represents a feature, a total of four columns of 1...
The data set sklearn Iris
sklearn · Scikit-learn (sklearn) is commonly used in machine learning third party modules, machine learning methods commonly used the package, including regression (Regression), dimensionality ...
Analyzing the iris data set
Reprinted address: https://www.cnblogs.com/mandy-study/p/7941365.html Analyzing the iris data set The following will combine the logistic regression model of Scikit-learn's official website to ...
More Recommendation
Iris data set
Iris data set load_iris() Keys: data: feature_names: target: Distinguish the first two features (sepal length and width) train_test_split: Shuffle (x and y need to be bound): The method here is to shu...
Iris data set visualization
Fisher data visualization Remove the "Iris-" character in the Species feature Seaborn visualization palette sns initialization, set() to set the theme and color palette relplot hue Joint dis...
Iris data set combat
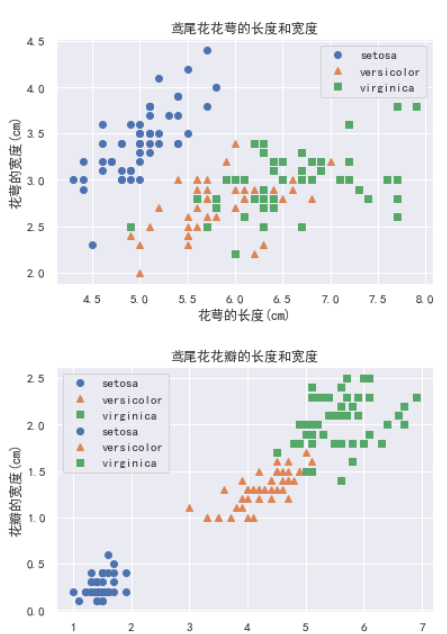
Iris data visualization Download seaborn library Read file data visualization Visualization of calyx length and width/petal length and width Data histogram Scatter chart KDE diagram KDE map is also ca...

Iris data set experiment
Install scikit-learn Scikit-Learn is a python-based machine learning module, including clustering, classification, regression and other mathematical analysis models. It can be used for data preprocess...

Visualization of iris data set
Iris data set The Iris dataset contains four attributes and one label The four attributes are Sepall length Calyx width Petal length Petal width A label to indicate which kind of iris Mountain Iris (S...